Share This Article
With the increasing prevalence of AI-powered information retrieval systems, we’re witnessing how Retrieval-Augmented Generation (RAG) has transformed large language models from isolated knowledge silos into dynamic systems capable of accessing external information. Yet as organizations deploy RAG at scale, they’re discovering a fundamental limitation: traditional RAG treats information as disconnected fragments, missing the rich web of relationships that give data its true meaning.

Consider a seemingly simple question: “What companies did former Apple executives found after leaving?” A traditional RAG system would struggle, searching for documents containing “Apple executives” and “founded companies” but missing the crucial connections between people, their employment history, and their subsequent ventures. This isn’t just a search problem—it’s a relationship problem. While standard RAG excels at finding relevant text chunks, it fails to capture how information interconnects, limiting its ability to answer questions that require understanding relationships, hierarchies, or multi-step reasoning.
Enter GraphRAG, an evolution that combines the semantic power of knowledge graphs with the retrieval capabilities of RAG. Building upon the graph database foundations we explored earlier, GraphRAG represents information as a network of entities and relationships, enabling systems to traverse connections, understand context, and deliver answers that traditional RAG simply cannot provide.
In this article, we’ll dive into:
- What GraphRAG is and how it enhances traditional RAG systems
- The technical implementation and three-stage architecture of GraphRAG
- Query processing techniques that leverage graph relationships
- Real-world use cases where GraphRAG excels
- Benefits and limitations compared to standard RAG
- Available implementation frameworks and tools
- Future directions for graph-enhanced retrieval
Understanding GraphRAG
What is GraphRAG?
GraphRAG represents a fusion of knowledge graph technology with Retrieval-Augmented Generation systems, creating an advanced approach to information retrieval and AI-powered responses. At its core, GraphRAG is “Retrieval Augmented Generation using a Knowledge Graph”—but this simple definition understates the profound shift in how information is structured and accessed.
Think of the difference between a library where books are scattered randomly on tables (traditional RAG) versus one where books are carefully organized by topic, with clear signs showing how subjects relate to each other (GraphRAG). In the first scenario, you might find relevant books, but you’d miss crucial connections. In the second, you can follow the relationships between topics, discovering connected knowledge you didn’t even know to look for.

Figure 1: GraphRAG vs Traditional RAG Architecture – This diagram illustrates the fundamental difference between GraphRAG’s connected knowledge representation and traditional RAG’s isolated chunk approach. Notice how GraphRAG maintains explicit relationships between entities while traditional RAG treats each chunk independently.
The conceptual architecture of GraphRAG addresses a fundamental limitation in conventional RAG implementations. Standard RAG systems excel at semantic similarity—finding text chunks that match the meaning of your query. But they struggle with queries that require understanding relationships between multiple pieces of information. They treat documents as isolated units, missing the interconnected nature of knowledge.
GraphRAG solves this by leveraging the graph structures we discussed in our previous article. Instead of storing disconnected text chunks, it represents information as nodes (entities) and edges (relationships) in a knowledge graph:
# Traditional RAG representation
documents = [
{"text": "Tim Cook is the CEO of Apple"},
{"text": "Steve Jobs co-founded Apple in 1976"},
{"text": "Jony Ive designed the iPhone"}
]
# GraphRAG representation (building on graph database concepts)
knowledge_graph = {
"nodes": [
{"id": "tim_cook", "type": "Person", "properties": {"name": "Tim Cook"}},
{"id": "apple", "type": "Company", "properties": {"name": "Apple"}},
{"id": "steve_jobs", "type": "Person", "properties": {"name": "Steve Jobs"}}
],
"edges": [
{"from": "tim_cook", "to": "apple", "type": "CEO_OF"},
{"from": "steve_jobs", "to": "apple", "type": "FOUNDED"},
{"from": "jony_ive", "to": "iphone", "type": "DESIGNED"}
]
}This graph structure enables GraphRAG to answer complex questions by following relationships, aggregating information from connected entities, and understanding the broader context of queries.
Why GraphRAG Enhances Traditional RAG
To grasp why GraphRAG has emerged as a critical evolution, let’s examine the specific limitations it addresses:
Relationship Blindness: Traditional RAG can find documents mentioning “Apple” and documents mentioning “Tim Cook,” but it doesn’t understand that Tim Cook is the CEO of Apple. This relationship blindness becomes critical when answering questions that require connecting multiple facts.
Lost Context: When chunking documents, traditional RAG often loses important contextual relationships. A chunk about a product might be separated from information about its creator, its company, or its impact. GraphRAG maintains these connections regardless of how information is chunked.
Multi-Hop Reasoning: Questions like “What products were designed by people who worked at companies founded by Stanford alumni?” require following multiple relationship hops. Traditional RAG would need to retrieve many documents and hope the LLM can piece together the connections. GraphRAG can traverse these relationships directly using the graph traversal mechanisms we explored earlier.
Aggregation Challenges: When information about an entity is scattered across multiple documents, traditional RAG struggles to provide comprehensive answers. GraphRAG can aggregate all information connected to an entity, regardless of its source.
The fundamental value proposition of GraphRAG is its ability to go beyond simple semantic similarity. While traditional RAG asks “What text is similar to this query?”, GraphRAG asks “What entities and relationships help answer this query?” This shift from document-centric to relationship-centric retrieval enables more precise and contextually relevant insights.
Technical Implementation
The Three-Stage Architecture
The technical architecture of GraphRAG operates through a well-defined three-stage process that distinguishes it from standard RAG approaches. Unlike the four-layer architecture of graph databases (processing, storage, API, and management), GraphRAG focuses specifically on the retrieval and generation workflow.

Figure 2: GraphRAG Three-Stage Architecture – This diagram shows the complete flow from document ingestion through entity extraction to final LLM-powered response generation. Each stage builds upon graph database capabilities to enable relationship-aware retrieval.
Stage 1: Graph Sourcing
The journey begins with Graph Sourcing—transforming unstructured text into a structured knowledge graph. This stage leverages the graph database concepts we discussed earlier but applies them specifically to the RAG context.
Unlike traditional RAG that simply chunks and embeds documents, Graph Sourcing involves sophisticated entity and relationship extraction:
class GraphRAGBuilder:
def __init__(self, entity_extractor, relation_extractor, graph_db):
self.entity_extractor = entity_extractor
self.relation_extractor = relation_extractor
self.graph_db = graph_db # Leverages graph database from previous article
def process_document(self, document):
"""
Extract entities and relationships for GraphRAG
"""
# Step 1: Extract entities using NLP models
entities = self.entity_extractor.extract(document)
# Step 2: Extract relationships between entities
relationships = self.relation_extractor.extract(document, entities)
# Step 3: Store in graph database with RAG-specific metadata
for entity in entities:
self.graph_db.add_node({
"id": entity.id,
"type": entity.type,
"properties": entity.properties,
"text_references": [document.id],
"embeddings": self.generate_embeddings(entity)
})
for rel in relationships:
self.graph_db.add_edge({
"from": rel.source_id,
"to": rel.target_id,
"type": rel.type,
"confidence": rel.confidence,
"source_document": document.id
})Interestingly, implementing GraphRAG doesn’t necessarily require a dedicated graph database. As we learned in our previous article, tools like PuppyGraph can map relational databases into graph structures without migrating data, making GraphRAG implementation more flexible.
Stage 2: Graph Retrieval
The second stage—Graph Retrieval—is where GraphRAG truly differentiates itself. Building on the traversal mechanisms we explored for graph databases, GraphRAG executes sophisticated queries to gather related information.
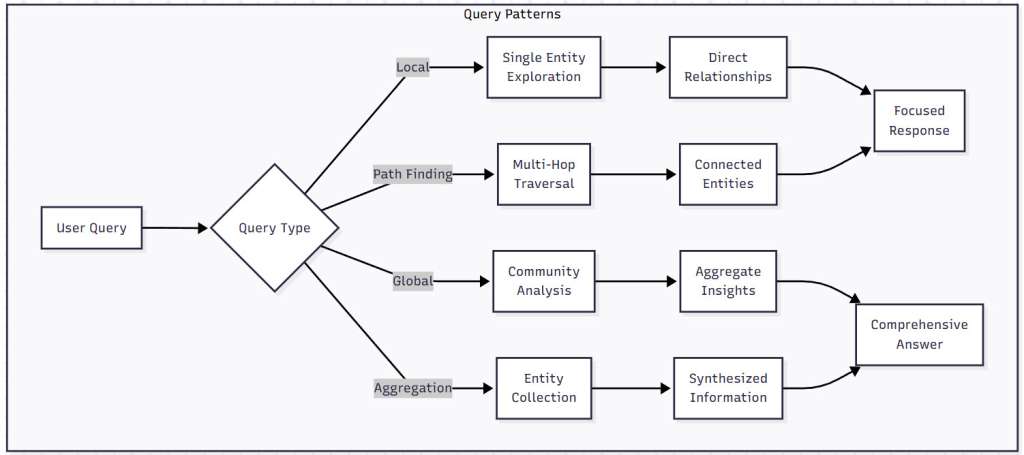
Figure 3: Query Patterns in GraphRAG – This flowchart illustrates how different query types (Local, Path Finding, Global, Aggregation) are processed through the graph to generate focused or comprehensive responses. Each pattern leverages different graph traversal strategies.
The retrieval process follows various patterns based on query type:
Pattern Matching: Finding specific structures in the graph
// Find all products designed by former Apple employees
MATCH (p:Person)-[:WORKED_AT]->(apple:Company {name: 'Apple'})
MATCH (p)-[:DESIGNED]->(product:Product)
WHERE p.end_date IS NOT NULL
RETURN p.name, product.name, product.propertiesGraph-Enhanced Vector Search: Combining embedding similarity with graph traversal
def graphrag_hybrid_retrieval(query, graph_db, embedding_model, top_k=5):
# Step 1: Vector search to find initial entities
query_embedding = embedding_model.encode(query)
initial_entities = graph_db.vector_search(query_embedding, top_k)
# Step 2: Graph traversal from initial entities
expanded_context = []
for entity in initial_entities:
# Get connected entities within 2 hops
neighbors = graph_db.traverse_bfs(entity.id, max_hops=2)
# Include relationship types in context
for neighbor in neighbors:
expanded_context.append({
"entity": neighbor,
"path": graph_db.get_path(entity.id, neighbor.id),
"relevance_score": calculate_relevance(neighbor, query)
})
return rank_and_filter(expanded_context)Community-Based Retrieval: Leveraging graph clustering for broad queries
- First identify relevant communities or clusters using algorithms like Leiden
- Then explore entities within those communities
- Particularly effective for thematic or domain-specific queries
Stage 3: LLM Generation
In the final stage, the retrieved graph information is transformed into natural language responses. Unlike traditional RAG that simply concatenates text chunks, GraphRAG provides structured context that helps the LLM understand relationships and generate more accurate answers.
def generate_graphrag_response(query, retrieved_graph_data, llm):
# Format graph data for LLM consumption
context = GraphContextFormatter.format(retrieved_graph_data)
prompt = f"""Based on the following knowledge graph information, answer the question.
Entities Found:
{format_entities_with_properties(retrieved_graph_data['nodes'])}
Relationship Paths:
{format_relationship_paths(retrieved_graph_data['paths'])}
Supporting Context:
{format_connected_information(retrieved_graph_data['expanded_context'])}
Question: {query}
Please provide a comprehensive answer using the graph relationships to connect information.
"""
return llm.generate(prompt, temperature=0.7)Query Processing in GraphRAG
Query Transformation
GraphRAG’s distinctive capability lies in how it processes natural language queries to leverage graph structures for retrieval. This process begins with transforming user questions into graph-aware operations.
Query transformation involves several sophisticated steps that build upon the graph query languages we discussed earlier:
- Entity Recognition: Identifying entities mentioned in the query
- Relationship Inference: Determining what relationships to explore
- Query Pattern Selection: Choosing the appropriate traversal strategy
For example, “What technologies did former Google engineers use in their startups?” transforms into:
- Entities: Google (Company), engineers (Person type)
- Relationships: WORKED_AT, FOUNDED, USES_TECHNOLOGY
- Pattern: Multi-hop traversal with temporal constraints
Hybrid Retrieval Techniques
Modern GraphRAG implementations employ sophisticated hybrid retrieval techniques that combine multiple search strategies:
Vector + Graph Traversal: Initial nodes found through semantic similarity, then expanded through relationship traversal. This approach leverages both semantic understanding and structural knowledge.
class HybridGraphRAGRetriever:
def retrieve(self, query, mode='adaptive'):
# Analyze query to determine retrieval strategy
query_analysis = self.analyze_query_intent(query)
if query_analysis['requires_relationships']:
# Use graph-first approach
return self.graph_enhanced_retrieval(query)
elif query_analysis['is_factual']:
# Use vector-first approach with graph enhancement
return self.vector_then_graph_retrieval(query)
else:
# Use community-based global search
return self.community_based_retrieval(query)Full-text + Vector + Graph: Systems might use keyword search for specific terms, vector search for semantic similarity, and graph traversal for relationship exploration—all in a single query.
Query Execution Patterns
Several execution patterns have emerged in GraphRAG implementations, each suited to different types of questions:
Local Search: Focuses on specific entities and their immediate connections. Ideal for questions about particular people, products, or organizations.
Global Search: Analyzes the entire graph or large communities to answer broad questions about trends, patterns, or aggregate information.
Path Finding: Discovers connections between entities that might be several relationships apart. Perfect for questions like “How is X connected to Y?”
Aggregation Queries: Collects information from multiple related entities to provide comprehensive answers. Essential for questions requiring synthesis from multiple sources.
Real-World Applications of GraphRAG
Complex Reasoning Scenarios
GraphRAG excels in situations requiring multi-hop reasoning or understanding of intricate relationships between entities. Building on the graph database use cases we explored, GraphRAG adds the power of natural language understanding:
Investigative Analysis: In fraud detection, GraphRAG can trace complex money flows through multiple entities and accounts while explaining the connections in natural language. A query like “Explain all suspicious transactions involving companies connected to John Doe” leverages both graph traversal and LLM explanation capabilities.
Root Cause Analysis: In IT operations, understanding why a system failed often requires tracing through dependencies. GraphRAG can follow the chain from a failed service through its dependencies, configurations, and recent changes, then generate a coherent explanation of the root cause.
Research Synthesis: Academic researchers can use GraphRAG to understand how concepts connect across papers. Questions like “How has the approach to transformer architectures evolved across different research groups?” require following citation networks and synthesizing information from multiple sources.
Relationship-Heavy Domains
Several professional domains that benefit from graph databases gain even more value from GraphRAG’s natural language interface:
Financial Analysis: Understanding corporate structures and investment relationships becomes conversational. Questions like “What companies in our portfolio have supply chain exposure to the semiconductor shortage?” receive detailed, relationship-aware answers.
Legal Document Analysis: Legal texts dense with references and precedents become navigable through natural language. GraphRAG can answer “How might changing clause 3.2 affect our obligations under related agreements?” by traversing the document graph.
Healthcare and Life Sciences: Patient care coordination improves when practitioners can ask “What treatment options exist for patients with condition X who are already taking medication Y?” and receive answers that consider drug interactions, comorbidities, and treatment pathways.
Enterprise Knowledge Management
Organizations with vast, interconnected knowledge bases find GraphRAG transformative for making their graph databases accessible to non-technical users:
Technical Documentation: Instead of requiring Cypher queries, engineers can ask “What systems depend on component X?” in natural language and receive comprehensive answers that traverse dependency graphs.
Customer Intelligence: Sales teams can ask “Which customers are connected to our highest-value accounts and might be interested in product Y?” without needing to understand graph query languages.
Competitive Intelligence: Strategic questions like “What technologies are being adopted by companies that hired from our competitors?” become answerable through natural language interfaces to complex relationship data.
Implementation Approaches
Neo4j GraphRAG Package
Neo4j, whose graph database we discussed earlier, offers a comprehensive GraphRAG package for Python that exemplifies enterprise-ready implementation:
from neo4j import GraphDatabase
from neo4j_graphrag import GraphRAG, HybridCypherRetriever
# Initialize connection to Neo4j
driver = GraphDatabase.driver("bolt://localhost:7687",
auth=("neo4j", "password"))
# Configure GraphRAG with hybrid retrieval
graphrag = GraphRAG(
driver=driver,
retriever=HybridCypherRetriever(
vector_index="content_embeddings",
fulltext_index="content_text",
graph_traversal_depth=3,
embedding_model="sentence-transformers/all-MiniLM-L6-v2",
cypher_generation_model="gpt-4"
)
)
# Execute GraphRAG query
response = graphrag.query(
"What products did former Apple employees create?",
include_sources=True,
include_reasoning_path=True,
max_results=10
)The Neo4j package provides several specialized retrievers:
- VectorRetriever: Pure semantic similarity search
- HybridRetriever: Combines vector and full-text search
- HybridCypherRetriever: Adds graph traversal capabilities
- Text2CypherRetriever: Converts natural language to Cypher queries
Microsoft GraphRAG
Microsoft has developed GraphRAG as a comprehensive “data pipeline and transformation suite” with unique approaches to community detection and summarization:
Hierarchical Community Structure: Microsoft’s implementation uses the Leiden algorithm to detect communities at multiple levels, creating a hierarchical organization of knowledge that enables both detailed and high-level queries.
Community Summaries: Each community gets an AI-generated summary, enabling efficient global search across the entire knowledge base without traversing every node.
from graphrag import GraphRAGPipeline
# Initialize Microsoft GraphRAG
pipeline = GraphRAGPipeline(
llm_model="gpt-4",
embedding_model="text-embedding-ada-002",
community_detection="leiden",
summarization_levels=3
)
# Process documents into hierarchical graph
knowledge_graph = pipeline.process_documents(
documents=document_collection,
chunk_size=300,
chunk_overlap=100,
entity_types=["Person", "Organization", "Technology", "Concept"]
)
# Query with community-aware retrieval
result = knowledge_graph.query(
"What are the main technological trends in AI?",
search_type="global",
use_community_summaries=True
)LlamaIndex PropertyGraph
LlamaIndex offers flexible PropertyGraph abstractions that integrate seamlessly with existing RAG pipelines:
from llama_index import PropertyGraphIndex
from llama_index.extractors import EntityExtractor, RelationExtractor
# Create property graph index
graph_index = PropertyGraphIndex.from_documents(
documents,
entity_extractor=EntityExtractor(
model="gpt-3.5-turbo",
entity_types=["Person", "Company", "Product"]
),
relation_extractor=RelationExtractor(
model="gpt-3.5-turbo",
relation_types=["WORKS_AT", "FOUNDED", "INVESTED_IN"]
),
embed_model="local:BAAI/bge-small-en-v1.5"
)
# Query with relationship awareness
query_engine = graph_index.as_query_engine(
retriever_mode="hybrid",
include_text=True,
response_mode="tree_summarize"
)Other Notable Implementations
PuppyGraph: Building on its “zero ETL” approach for graph databases, PuppyGraph’s Agentic GraphRAG can execute multiple queries while reasoning about results.
FalkorDB: Focuses on high-performance graph operations with deep LLM integration, particularly suited for real-time GraphRAG applications.
Amazon Neptune: Extends its graph database capabilities with GraphRAG patterns, ideal for organizations already using AWS infrastructure.
Benefits and Challenges
Advantages of GraphRAG
The shift from flat document retrieval to graph-based knowledge access brings several compelling advantages beyond those offered by graph databases alone:
Relationship-Aware Responses: Perhaps the most significant benefit is the ability to generate answers that understand and explain relationships. Unlike traditional RAG that might list facts, GraphRAG can explain how things connect.
Multi-Hop Reasoning in Natural Language: GraphRAG can follow chains of relationships and explain the path. “Who are the investors in companies founded by MIT alumni in the biotechnology sector?” receives not just a list but an explanation of the connections.
Improved Accuracy and Completeness: By maintaining entity relationships and enabling information aggregation from multiple sources, GraphRAG typically delivers more accurate and complete answers than traditional RAG systems.
Enhanced Explainability: Graph traversal paths provide clear explanations for how the system arrived at an answer. Users can see exactly which relationships were followed, building trust and enabling verification.
Reduced Hallucination: The structured nature of graph data provides factual grounding that reduces LLM hallucination compared to free-form text generation.
Challenges and Limitations
Despite its advantages, GraphRAG faces significant challenges beyond those of standard graph databases:
Graph Construction Complexity: Building high-quality knowledge graphs from diverse data sources requires:
- Accurate entity extraction from unstructured text
- Reliable relationship detection and classification
- Effective entity disambiguation across documents
- Continuous maintenance as information changes
Query Intent Understanding: Converting natural language questions into effective graph queries remains challenging. The system must:
- Understand which entities and relationships are relevant
- Determine the appropriate traversal depth
- Balance completeness with relevance
Scalability at Multiple Levels: GraphRAG must handle:
- Large-scale graphs (millions of nodes)
- High query volumes
- Complex multi-hop traversals
- Real-time response requirements
Implementation Complexity: GraphRAG systems require expertise in:
- Graph database technologies
- Natural language processing
- Entity extraction and linking
- Traditional RAG components
- Prompt engineering for graph context
Future Directions
Enhanced Knowledge Graph Construction
The future of GraphRAG hinges partly on making graph construction more automated and accurate:
- Self-supervised learning for relationship extraction
- Active learning approaches that improve from user feedback
- Automated ontology learning from domain documents
- Real-time graph updates from streaming data sources
Multimodal GraphRAG
As AI systems increasingly work with diverse data types, GraphRAG is evolving to incorporate multimodal information:
- Visual entities extracted from images and videos
- Audio relationships from speech and sound
- Cross-modal relationships linking text, vision, and audio
- Unified embeddings that work across modalities
Imagine asking “Show me all products that look similar to this image and were mentioned in our last earnings call”—multimodal GraphRAG will make such queries possible.
Explainable GraphRAG
Future systems will provide even better explanations of their reasoning:
- Interactive visualizations of graph traversal paths
- Natural language explanations of why certain paths were chosen
- Confidence scores for different reasoning steps
- Alternative path suggestions for exploration
Real-Time Knowledge Integration
Static knowledge graphs will give way to dynamic systems that continuously integrate new information:
- Streaming updates from news feeds and databases
- Automatic relationship inference from new data
- Temporal graphs that track how relationships change
- Predictive capabilities based on graph evolution patterns
Conclusion
GraphRAG represents a fundamental evolution in how we approach information retrieval for AI systems. By building upon graph database technology and adding natural language understanding, it addresses critical limitations that have long plagued traditional RAG implementations. The ability to understand and traverse connections between entities transforms what questions we can ask and what insights we can derive.
The journey from keyword search to semantic retrieval to graph-enhanced generation marks a progression toward more intelligent information systems. We’re no longer limited to finding documents that mention our search terms—we can now explore the rich web of relationships that give information its true meaning. This capability proves invaluable across domains where connections matter: investigating financial networks, understanding scientific relationships, navigating legal precedents, or managing enterprise knowledge.
While GraphRAG comes with increased complexity in implementation and maintenance compared to both traditional RAG and standalone graph databases, the benefits for appropriate use cases are compelling. Organizations dealing with relationship-rich domains, complex reasoning requirements, or interconnected knowledge bases find that GraphRAG’s advantages far outweigh its challenges. The ability to answer previously impossible questions, provide explainable reasoning paths, and maintain knowledge coherence justifies the additional investment.
Looking ahead, the convergence of advances in knowledge graph construction, multimodal AI, and real-time processing points toward even more capable GraphRAG systems. As these technologies mature, we can expect GraphRAG to become not just an enhancement to RAG, but an essential component of intelligent systems that truly understand the connected nature of information.
Practical Takeaways
Assess Your Use Case: GraphRAG excels when relationships matter. If your queries frequently involve connections between entities, multi-hop reasoning, or comprehensive aggregation, GraphRAG is worth the investment.
Start with Your Graph Database: If you already have a graph database (as discussed in our previous article), adding GraphRAG capabilities is a natural evolution that makes your data more accessible.
Choose the Right Implementation: Select frameworks based on your existing infrastructure—Neo4j for native graph databases, Microsoft GraphRAG for hierarchical analysis, or LlamaIndex for flexible integration.
Plan for Maintenance: Budget time and resources for ongoing graph curation, entity resolution, and relationship updates. The quality of your graph directly impacts GraphRAG performance.
Combine Approaches: Use hybrid retrieval strategies that leverage both vector similarity and graph traversal. Pure graph-based retrieval isn’t always optimal—let the query type guide your approach.
For AI practitioners, the message is clear: while traditional RAG remains valuable for many use cases, understanding and leveraging GraphRAG is becoming increasingly important. As our information becomes more interconnected and our questions more complex, the ability to navigate knowledge as a graph rather than a collection of documents will separate truly intelligent systems from simple retrieval engines. The future of AI-powered information access is not just about finding relevant text—it’s about understanding the relationships that connect ideas, entities, and knowledge into a coherent whole.
References
[1] Microsoft Research, “GraphRAG: Unlocking LLM Discovery on Narrative Private Data,” https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/ (2024).[2] Neo4j, “GraphRAG: Implementing Graph-Enhanced Retrieval,” https://neo4j.com/developer-blog/graphrag-implementation-guide/ (2024).
[3] Edge, Darren, et al., “From Local to Global: A Graph RAG Approach to Query-Focused Summarization,” arXiv preprint arXiv:2404.16130, 2024.
[4] LlamaIndex, “Building GraphRAG Applications with Property Graphs,” https://docs.llamaindex.ai/en/stable/examples/property_graph/graph_rag_guide/ (2024).
[5] PuppyGraph, “Agentic GraphRAG: Multi-Query Reasoning with Zero ETL,” https://www.puppygraph.com/blog/agentic-graphrag (2024).
[6] Neo4j, “GraphRAG Python Package Documentation,” https://neo4j.com/docs/neo4j-graphrag-python/current/ (2024).
[7] Microsoft GitHub, “GraphRAG: A modular graph-based Retrieval-Augmented Generation system,” https://github.com/microsoft/graphrag (2024).
[8] FalkorDB, “Real-Time GraphRAG with FalkorDB,” https://www.falkordb.com/blog/real-time-graphrag/ (2024).
[9] Amazon Web Services, “Building GraphRAG Applications with Amazon Neptune,” https://aws.amazon.com/blogs/database/graphrag-with-neptune/ (2024).
[10] Huang, Qingqing, et al., “Knowledge Graph Enhanced Language Models: A Survey,” ACM Computing Surveys, vol. 56, no. 3, 2024.
[11] Zhang, Chen, et al., “G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering,” arXiv preprint arXiv:2402.07630, 2024.
[12] Neo4j, “Hybrid Retrieval Strategies in GraphRAG,” https://neo4j.com/blog/hybrid-retrieval-graphrag-strategies/ (2024).
[13] LangChain, “GraphRAG with LangGraph: Building Knowledge-Aware Applications,” https://blog.langchain.dev/graphrag-langgraph-integration/ (2024).
[14] Anthropic Research, “Reducing Hallucination in RAG Systems with Graph Structures,” https://www.anthropic.com/research/graph-structured-rag (2024).
[15] Google Research, “Multi-Modal Knowledge Graphs for Next-Generation RAG,” Proceedings of ICML 2024.
[16] Stanford AI Lab, “Benchmarking GraphRAG: Performance Analysis Across Domains,” Technical Report, 2024.
[17] Meta AI Research, “Dynamic Knowledge Graphs for Real-Time RAG Applications,” arXiv preprint arXiv:2403.09234, 2024.
[18] IBM Research, “Enterprise GraphRAG: Lessons from Large-Scale Deployments,” IBM Technical Papers, 2024.
[19] Databricks, “Implementing GraphRAG at Scale with Delta Lake and Neo4j,” https://www.databricks.com/blog/graphrag-at-scale (2024).
[20] DeepMind, “Temporal Knowledge Graphs for Time-Aware RAG Systems,” Nature Machine Intelligence, vol. 6, 2024.
