Share This Article
In the rapidly evolving landscape of AI development, we’re witnessing an explosion of agent-based systems that promise to revolutionize how we build intelligent applications. Yet beneath this excitement lies a harsh reality: most AI agents in production are either too rigid to handle complex workflows or too chaotic to deliver reliable results. Traditional approaches force us to choose between the flexibility of autonomous agents and the predictability of hardcoded pipelines—a choice that leaves us compromising on either capability or reliability.

As AI practitioners, we’ve all felt the pain of orchestrating multi-step workflows where one agent’s output feeds into another’s input, only to watch the entire system fail because of a single malformed response. Or we’ve built rigid pipelines that work perfectly for our test cases but crumble when faced with the messy reality of production data. The problem isn’t with the individual components—modern LLMs are remarkably capable, and validation frameworks like Pydantic are battle-tested. The challenge is making them work together in ways that are both powerful and predictable.
This is where the convergence of two complementary technologies changes everything: Langgraph’s stateful workflow orchestration and Pydantic AI’s type-safe agent framework. Think of it as bringing the best of software engineering—with its emphasis on reliability and maintainability—to the wild world of AI agents. By combining flexible graph-based orchestration with strict data validation, we can finally build AI systems that are sophisticated enough to handle complex real-world problems while being robust enough to run in production.
The magic happens when you realize these aren’t competing paradigms but complementary ones. Langgraph gives us the ability to model complex, multi-step workflows as directed graphs, while Pydantic AI ensures that data flowing between nodes maintains its integrity. It’s like having a brilliant project manager (Langgraph) working with a meticulous quality controller (Pydantic AI) to deliver results that are both innovative and reliable.
In this article, we’ll dive into:
- Understanding the fundamentals of Langgraph and Pydantic AI and how they complement each other
- The technical architecture that enables reliable workflow orchestration with type safety
- Implementation patterns for building production-ready agent systems
- Practical examples of multi-agent orchestration with complete code implementations
- Strategies for handling complex workflows, state management, and error recovery
- Performance optimization techniques for scaling agent systems
- Real-world applications and case studies across different industries
Understanding Langgraph and Pydantic AI
What Are Langgraph and Pydantic AI?
Let’s start with the fundamentals. If you’ve been building AI applications, you’ve probably encountered the challenge of managing complex workflows. Maybe you’ve chained together multiple LLM calls, each dependent on the previous one’s output. Or perhaps you’ve built systems where different agents need to collaborate, share state, and make decisions based on evolving context. This is exactly where Langgraph and Pydantic AI shine—but in beautifully complementary ways.
Langgraph is a framework for building stateful, multi-agent applications with LLMs. At its core, it models your AI workflows as directed graphs where nodes represent distinct processing steps and edges define the flow of execution. But here’s what makes it special: unlike simple sequential chains, Langgraph treats both nodes and transitions as first-class citizens. This means you can build workflows with conditional branching, parallel execution, and even cycles—all while maintaining state across the entire execution.
Pydantic AI, on the other hand, brings type safety and data validation to the chaotic world of LLM outputs. Built on the rock-solid foundation of Pydantic (which you might know from FastAPI), it ensures that every piece of data flowing through your system conforms to well-defined schemas. When an LLM generates a response, Pydantic AI validates it against your models, catching errors before they propagate through your system.
You can think of this combination like a well-orchestrated kitchen. Langgraph is your head chef, directing the flow of work between different stations, deciding what needs to be done in parallel, and maintaining the overall vision of the dish. Pydantic AI is your quality control, ensuring that every ingredient meets standards and that what goes from one station to another is exactly what’s expected. Together, they transform a potentially chaotic process into a smooth, reliable operation.
The Power of Integration
Here’s where things get really interesting. When you combine Langgraph’s orchestration capabilities with Pydantic AI’s validation framework, you get something greater than the sum of its parts:
from langgraph.graph import StateGraph, State
from pydantic import BaseModel, Field
from pydantic_ai import Agent
from typing import List, Dict, Optional
# Define our data models with Pydantic
class ResearchQuery(BaseModel):
"""Structured representation of a research query."""
topic: str = Field(..., description="Main research topic")
subtopics: List[str] = Field(default_factory=list, description="Specific areas to explore")
max_sources: int = Field(default=5, ge=1, le=20, description="Maximum number of sources to find")
class ResearchResult(BaseModel):
"""Validated research output."""
summary: str = Field(..., description="Executive summary of findings")
key_insights: List[str] = Field(..., min_items=1, description="Main discoveries")
sources: List[Dict[str, str]] = Field(..., description="Citations with title and URL")
confidence_score: float = Field(..., ge=0, le=1, description="Confidence in the findings")
# Create Pydantic AI agents for each step
research_agent = Agent(
'openai:gpt-4o',
result_type=ResearchResult,
system_prompt="You are a research specialist. Analyze information and extract key insights."
)
# Define Langgraph state
class ResearchState(TypedDict):
query: ResearchQuery
raw_data: Optional[str]
research_result: Optional[ResearchResult]
status: str
# Build the workflow graph
workflow = StateGraph(ResearchState)
# Node functions that leverage Pydantic AI agents
async def gather_data(state: ResearchState) -> Dict:
"""Gather raw data based on the research query."""
# In a real implementation, this might call APIs or search databases
# For now, we'll simulate with a simple prompt
query = state["query"]
data = f"Simulated data about {query.topic} covering {', '.join(query.subtopics)}"
return {"raw_data": data, "status": "data_gathered"}
async def analyze_data(state: ResearchState) -> Dict:
"""Use Pydantic AI agent to analyze and structure the data."""
result = await research_agent.run(
f"Analyze this data and extract insights: {state['raw_data']}"
)
# The result is guaranteed to be a valid ResearchResult
return {"research_result": result.data, "status": "analysis_complete"}
# Wire up the graph
workflow.add_node("gather", gather_data)
workflow.add_node("analyze", analyze_data)
workflow.add_edge("gather", "analyze")
workflow.set_entry_point("gather")
# Compile and use
app = workflow.compile()What makes this powerful is how naturally these technologies work together. Langgraph handles the flow—deciding what happens when, managing state between steps, and potentially routing to different paths based on conditions. Pydantic AI ensures that at every step, the data conforms to our expectations. No more wondering if the LLM included all the required fields or if the format is correct.
Langgraph vs. Other Orchestration Frameworks
To really appreciate what Langgraph brings to the table, let’s compare it with traditional approaches:
| Feature | Langgraph | Traditional Chains | Workflow Engines |
|---|---|---|---|
| State Management | Built-in, persistent across nodes | Limited, often passed manually | Varies, often external |
| Conditional Logic | Native support via edges | Requires workarounds | Usually supported |
| Parallel Execution | First-class with proper state handling | Difficult to implement | Depends on engine |
| Error Recovery | Can route to error handlers | Typically fails entire chain | Varies by implementation |
| Debugging | Visualizable graph structure | Linear, harder to trace | Often good tooling |
| LLM Integration | Designed for it | Retrofitted | Usually generic |
The key insight is that Langgraph was built specifically for LLM applications, not adapted from generic workflow engines. This shows in features like checkpointing (saving state for long-running workflows) and native support for the kinds of conditional logic common in agent systems.

Figure 1: Langgraph vs Sequential Chains – This diagram illustrates the fundamental difference between Langgraph’s graph-based approach and traditional sequential chains. Notice how Langgraph allows for conditional branching and multiple paths to the same endpoint, while sequential chains force a rigid, linear flow.
The Technical Architecture Behind the Integration
The Four-Layer Architecture
Understanding how Langgraph and Pydantic AI work together requires looking at the system architecture. Think of it as a well-designed building where each floor serves a specific purpose, and together they create something both functional and elegant.
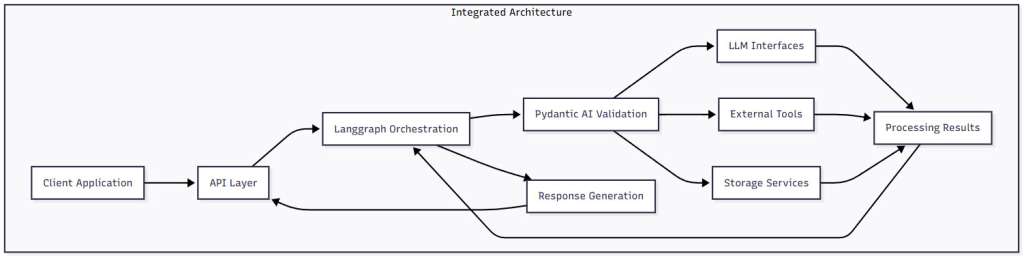
Figure 2: Integrated Architecture – This diagram shows how Langgraph and Pydantic AI work together in a layered architecture. Data flows from the client through Langgraph’s orchestration layer, where Pydantic AI validates all inputs and outputs before they interact with LLMs, tools, or storage systems.
Let’s break down each layer:
Orchestration Layer (Langgraph)
This is where the magic of workflow management happens. Langgraph maintains the overall state of your application and manages transitions between different processing nodes. It’s responsible for:
- Deciding which node to execute next based on the current state
- Managing parallel execution when multiple paths can be taken
- Handling checkpoints for long-running workflows
- Providing retry and error recovery mechanisms
Validation Layer (Pydantic AI)
Every piece of data that flows through your system passes through this layer. Pydantic AI ensures that:
- LLM outputs conform to expected schemas
- Tool inputs are properly formatted before execution
- State transitions only happen with valid data
- Type mismatches are caught immediately, not three steps later
Execution Layer
This is where the actual work happens. The execution layer coordinates:
- LLM invocations with proper prompt formatting
- Tool execution with validated parameters
- External API calls with proper error handling
- Result aggregation from parallel operations
Integration Layer
The bottom layer handles all external interactions:
- Database connections for state persistence
- API integrations for external services
- Message queues for async processing
- Monitoring and logging infrastructure
State Transitions and Data Flow
One of the most powerful aspects of this integration is how state transitions work. Let me show you with a practical example:
from langgraph.graph import StateGraph, END
from pydantic import BaseModel, Field, validator
from pydantic_ai import Agent
from typing import List, Optional, Literal
from enum import Enum
# Define workflow states with Pydantic models
class DocumentStatus(str, Enum):
PENDING = "pending"
EXTRACTING = "extracting"
ANALYZING = "analyzing"
REVIEWING = "reviewing"
COMPLETE = "complete"
ERROR = "error"
class DocumentAnalysisState(BaseModel):
"""State that flows through our document analysis workflow."""
document_id: str
content: str
status: DocumentStatus = DocumentStatus.PENDING
extracted_entities: Optional[List[str]] = None
sentiment_score: Optional[float] = None
summary: Optional[str] = None
review_notes: Optional[str] = None
error_message: Optional[str] = None
@validator('sentiment_score')
def validate_sentiment(cls, v):
if v is not None and not -1 <= v <= 1:
raise ValueError("Sentiment score must be between -1 and 1")
return v
# Create specialized agents for each task
entity_extractor = Agent(
'openai:gpt-4o',
system_prompt="Extract all named entities (people, organizations, locations) from the text."
)
sentiment_analyzer = Agent(
'openai:gpt-4o',
system_prompt="Analyze the sentiment of the text. Return a score between -1 (negative) and 1 (positive)."
)
summarizer = Agent(
'openai:gpt-4o',
system_prompt="Create a concise summary of the document's main points."
)
# Define node functions
async def extract_entities(state: DocumentAnalysisState) -> Dict:
"""Extract entities from the document."""
try:
result = await entity_extractor.run(state.content)
# Parse the result and extract entity list
entities = parse_entities(result.data) # Custom parsing function
return {
"extracted_entities": entities,
"status": DocumentStatus.ANALYZING
}
except Exception as e:
return {
"status": DocumentStatus.ERROR,
"error_message": f"Entity extraction failed: {str(e)}"
}
async def analyze_sentiment(state: DocumentAnalysisState) -> Dict:
"""Analyze document sentiment."""
try:
result = await sentiment_analyzer.run(state.content)
score = float(result.data) # Pydantic AI ensures this is valid
return {
"sentiment_score": score,
"status": DocumentStatus.REVIEWING
}
except Exception as e:
return {
"status": DocumentStatus.ERROR,
"error_message": f"Sentiment analysis failed: {str(e)}"
}
async def create_summary(state: DocumentAnalysisState) -> Dict:
"""Generate document summary."""
# Include extracted entities in the summary for context
context = f"Document contains entities: {', '.join(state.extracted_entities or [])}"
prompt = f"{context}\n\nDocument: {state.content}"
result = await summarizer.run(prompt)
return {
"summary": result.data,
"status": DocumentStatus.COMPLETE
}
# Build the workflow
def create_document_workflow():
workflow = StateGraph(DocumentAnalysisState)
# Add nodes
workflow.add_node("extract", extract_entities)
workflow.add_node("sentiment", analyze_sentiment)
workflow.add_node("summarize", create_summary)
# Define the flow
workflow.set_entry_point("extract")
# Conditional routing based on status
def route_after_extraction(state: DocumentAnalysisState) -> str:
if state.status == DocumentStatus.ERROR:
return END
return "sentiment"
workflow.add_conditional_edges("extract", route_after_extraction)
workflow.add_edge("sentiment", "summarize")
workflow.add_edge("summarize", END)
return workflow.compile()
# Use the workflow
app = create_document_workflow()
# Process a document
initial_state = DocumentAnalysisState(
document_id="doc123",
content="Apple Inc. announced record profits in Q4 2024..."
)
result = await app.ainvoke(initial_state)
print(f"Summary: {result.summary}")
print(f"Sentiment: {result.sentiment_score}")
print(f"Entities: {result.extracted_entities}")What’s brilliant about this approach is how it handles failures gracefully. If entity extraction fails, the workflow can route to an error state instead of crashing the entire pipeline. The state is preserved, so you can resume from where things went wrong.
Transition Mechanisms
Langgraph provides several powerful patterns for controlling flow through your workflow:
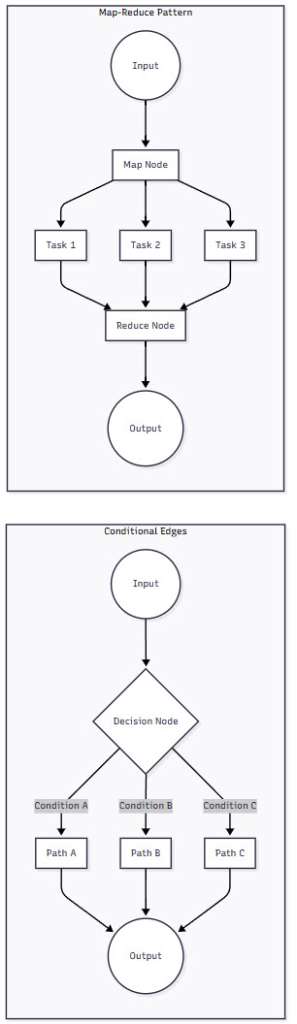
Figure 3: Transition Mechanisms in Langgraph – This diagram illustrates two key patterns in Langgraph: conditional edges for dynamic routing and map-reduce for parallel processing. These patterns enable sophisticated workflows that adapt to data and scale with load.
Let’s implement a map-reduce pattern for parallel document processing:
from langgraph.graph import StateGraph
from typing import List, Dict
import asyncio
class BatchProcessingState(BaseModel):
"""State for processing multiple documents in parallel."""
documents: List[Dict[str, str]]
processed_results: List[Dict] = Field(default_factory=list)
aggregated_summary: Optional[str] = None
async def map_documents(state: BatchProcessingState) -> Dict:
"""Map phase - process each document in parallel."""
async def process_single_doc(doc):
# Create individual workflow for each document
doc_state = DocumentAnalysisState(
document_id=doc["id"],
content=doc["content"]
)
# Process through our document workflow
result = await app.ainvoke(doc_state)
return result.dict()
# Process all documents in parallel
tasks = [process_single_doc(doc) for doc in state.documents]
results = await asyncio.gather(*tasks)
return {"processed_results": results}
async def reduce_results(state: BatchProcessingState) -> Dict:
"""Reduce phase - aggregate results into final summary."""
# Collect all summaries
summaries = [r["summary"] for r in state.processed_results if r.get("summary")]
# Use an agent to create an aggregated summary
aggregator = Agent(
'openai:gpt-4o',
system_prompt="Create a comprehensive summary combining multiple document summaries."
)
combined_text = "\n\n".join(f"Document {i+1}: {s}" for i, s in enumerate(summaries))
result = await aggregator.run(combined_text)
return {"aggregated_summary": result.data}
# Create batch processing workflow
batch_workflow = StateGraph(BatchProcessingState)
batch_workflow.add_node("map", map_documents)
batch_workflow.add_node("reduce", reduce_results)
batch_workflow.add_edge("map", "reduce")
batch_workflow.set_entry_point("map")
batch_app = batch_workflow.compile()This pattern is incredibly powerful for scaling your agent systems. Instead of processing documents sequentially, you can parallelize the work while still maintaining type safety and validation at every step.
Building Production-Ready Systems
Error Handling and Recovery
One of the biggest challenges in production AI systems is handling the inevitable failures gracefully. LLMs can timeout, APIs can be down, and sometimes the output just doesn’t make sense. Here’s how to build resilient workflows:
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from typing import Optional, List
import asyncio
from datetime import datetime
class ResilientState(BaseModel):
"""State with built-in error tracking and recovery."""
task_id: str
input_data: str
current_step: str = "start"
retry_count: int = 0
max_retries: int = 3
errors: List[Dict] = Field(default_factory=list)
partial_results: Dict = Field(default_factory=dict)
final_result: Optional[str] = None
def record_error(self, step: str, error: Exception):
"""Record an error for debugging and recovery."""
self.errors.append({
"step": step,
"error": str(error),
"timestamp": datetime.now().isoformat(),
"retry_count": self.retry_count
})
class RetryableAgent:
"""Wrapper for Pydantic AI agents with retry logic."""
def __init__(self, agent: Agent, max_retries: int = 3, backoff_factor: float = 2.0):
self.agent = agent
self.max_retries = max_retries
self.backoff_factor = backoff_factor
async def run_with_retry(self, prompt: str, state: ResilientState) -> Optional[str]:
"""Execute agent with exponential backoff retry."""
for attempt in range(self.max_retries):
try:
result = await self.agent.run(prompt)
return result.data
except Exception as e:
state.record_error(state.current_step, e)
if attempt < self.max_retries - 1:
# Exponential backoff
wait_time = self.backoff_factor ** attempt
await asyncio.sleep(wait_time)
else:
# Final attempt failed
return None
return None
# Create resilient workflow
def create_resilient_workflow():
workflow = StateGraph(ResilientState)
# Initialize retryable agents
analyzer = RetryableAgent(
Agent('openai:gpt-4o', system_prompt="Analyze the provided text.")
)
enhancer = RetryableAgent(
Agent('openai:gpt-4o', system_prompt="Enhance and improve the analysis.")
)
async def analyze_with_fallback(state: ResilientState) -> Dict:
"""Analyze with fallback options."""
state.current_step = "analysis"
# Try primary analysis
result = await analyzer.run_with_retry(state.input_data, state)
if result:
return {
"partial_results": {"analysis": result},
"current_step": "enhancement"
}
# Fallback to simpler analysis
fallback_agent = Agent(
'openai:gpt-3.5-turbo',
system_prompt="Provide a basic analysis of the text."
)
fallback_result = await fallback_agent.run(state.input_data)
return {
"partial_results": {"analysis": fallback_result.data, "used_fallback": True},
"current_step": "enhancement"
}
async def enhance_with_recovery(state: ResilientState) -> Dict:
"""Enhance analysis with error recovery."""
state.current_step = "enhancement"
if not state.partial_results.get("analysis"):
return {
"final_result": "Analysis failed - no results to enhance",
"current_step": "complete"
}
analysis = state.partial_results["analysis"]
result = await enhancer.run_with_retry(
f"Enhance this analysis: {analysis}",
state
)
if result:
return {
"final_result": result,
"current_step": "complete"
}
# If enhancement fails, return original analysis
return {
"final_result": analysis,
"current_step": "complete"
}
# Build workflow with error paths
workflow.add_node("analyze", analyze_with_fallback)
workflow.add_node("enhance", enhance_with_recovery)
workflow.set_entry_point("analyze")
workflow.add_edge("analyze", "enhance")
workflow.add_edge("enhance", END)
return workflow.compile()This approach gives you multiple layers of resilience:
- Automatic retries with exponential backoff
- Fallback to simpler models if the primary fails
- Partial result preservation so you don’t lose everything on failure
- Detailed error tracking for debugging
State Management Best Practices
Managing state effectively is crucial for complex workflows. Here are patterns that work well in production:
from langgraph.graph import StateGraph
from langgraph.checkpoint import MemorySaver
from pydantic import BaseModel, Field
from typing import Dict, List, Optional
import json
class CheckpointableState(BaseModel):
"""State designed for efficient checkpointing."""
# Minimal core state
workflow_id: str
current_phase: str
# Separate large data that can be stored externally
data_references: Dict[str, str] = Field(
default_factory=dict,
description="References to external data storage"
)
# Computed properties that don't need persistence
_cache: Dict = {} # Not persisted
class Config:
# Only persist defined fields
fields = {"workflow_id", "current_phase", "data_references"}
def store_large_data(self, key: str, data: any) -> str:
"""Store large data externally and keep reference."""
# In production, this would use S3, Redis, etc.
reference = f"s3://bucket/{self.workflow_id}/{key}"
# Simulate storage
self._cache[reference] = data
self.data_references[key] = reference
return reference
def retrieve_data(self, key: str) -> any:
"""Retrieve data using reference."""
reference = self.data_references.get(key)
if reference:
# In production, fetch from external storage
return self._cache.get(reference)
return None
# Create workflow with checkpointing
def create_checkpointed_workflow():
# Initialize with memory saver for checkpointing
checkpointer = MemorySaver()
workflow = StateGraph(CheckpointableState)
async def process_phase_1(state: CheckpointableState) -> Dict:
"""First phase - might take a long time."""
# Simulate processing
result = {"processed": "large amount of data"}
# Store large result externally
state.store_large_data("phase1_result", result)
return {
"current_phase": "phase2",
"data_references": state.data_references
}
async def process_phase_2(state: CheckpointableState) -> Dict:
"""Second phase - uses results from phase 1."""
# Retrieve previous results
phase1_data = state.retrieve_data("phase1_result")
if not phase1_data:
raise ValueError("Phase 1 data not found")
# Continue processing
final_result = f"Completed processing of {phase1_data}"
return {
"current_phase": "complete"
}
workflow.add_node("phase1", process_phase_1)
workflow.add_node("phase2", process_phase_2)
workflow.set_entry_point("phase1")
workflow.add_edge("phase1", "phase2")
workflow.add_edge("phase2", END)
# Compile with checkpointing
return workflow.compile(checkpointer=checkpointer)
# Use with checkpointing
app = create_checkpointed_workflow()
# Start processing
initial_state = CheckpointableState(
workflow_id="job-123",
current_phase="phase1"
)
# This can be interrupted and resumed
config = {"configurable": {"thread_id": "job-123"}}
result = await app.ainvoke(initial_state, config=config)
# Later, resume from checkpoint if needed
# resumed_result = await app.ainvoke(None, config=config)Multi-Agent Orchestration
Real-world applications often require multiple specialized agents working together. Here’s how to orchestrate them effectively:
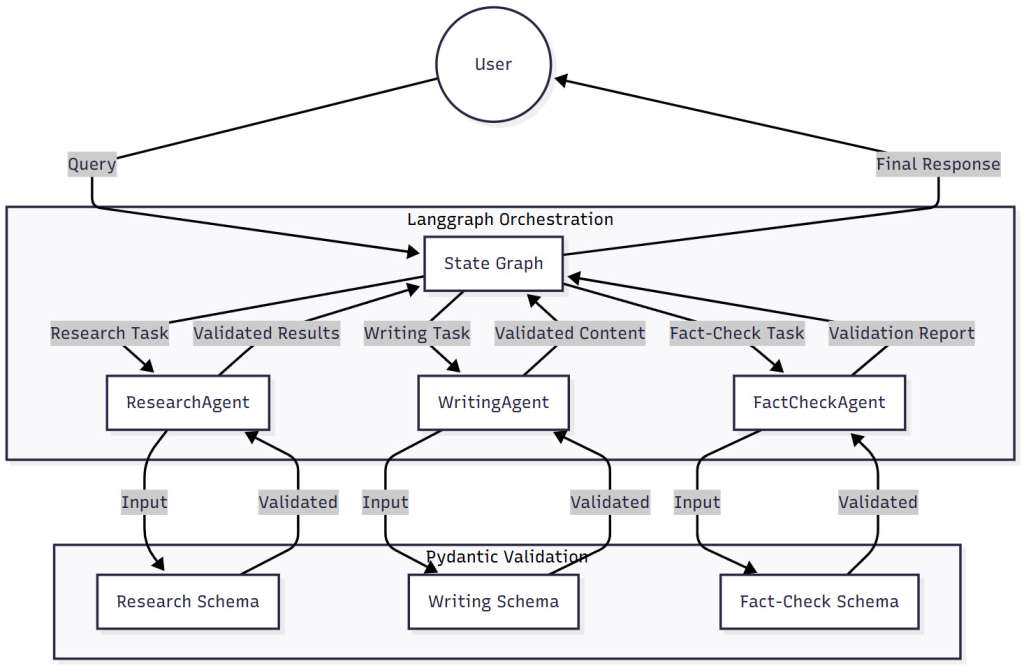
Figure 4: Multi-Agent Orchestration Workflow – This diagram shows how multiple specialized agents (research, writing, fact-checking) work together in a Langgraph workflow, with Pydantic AI ensuring data validation at each handoff point.
Let’s implement this multi-agent system:
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from pydantic_ai import Agent
from typing import List, Dict, Optional
# Define specialized schemas for each agent
class ResearchFindings(BaseModel):
"""Output from research agent."""
topic: str
key_facts: List[str] = Field(..., min_items=3, max_items=10)
sources: List[str] = Field(..., min_items=1)
confidence: float = Field(..., ge=0, le=1)
class WrittenContent(BaseModel):
"""Output from writing agent."""
title: str
introduction: str
body_paragraphs: List[str] = Field(..., min_items=2)
conclusion: str
word_count: int
class FactCheckReport(BaseModel):
"""Output from fact-checking agent."""
verified_facts: List[Dict[str, bool]]
accuracy_score: float = Field(..., ge=0, le=1)
corrections_needed: List[str] = Field(default_factory=list)
recommendation: str
# Create specialized agents
research_agent = Agent(
'openai:gpt-4o',
result_type=ResearchFindings,
system_prompt="""You are a meticulous research specialist.
Find accurate, relevant information and always cite sources."""
)
writing_agent = Agent(
'openai:gpt-4o',
result_type=WrittenContent,
system_prompt="""You are a skilled content writer.
Create engaging, well-structured content based on research findings."""
)
fact_check_agent = Agent(
'openai:gpt-4o',
result_type=FactCheckReport,
system_prompt="""You are a fact-checking expert.
Verify claims, check sources, and ensure accuracy."""
)
# Define the multi-agent workflow state
class ContentCreationState(BaseModel):
"""State for multi-agent content creation workflow."""
user_request: str
research_findings: Optional[ResearchFindings] = None
written_content: Optional[WrittenContent] = None
fact_check_report: Optional[FactCheckReport] = None
final_content: Optional[str] = None
workflow_status: str = "started"
# Implement workflow nodes
async def conduct_research(state: ContentCreationState) -> Dict:
"""Research phase using specialized agent."""
result = await research_agent.run(
f"Research this topic thoroughly: {state.user_request}"
)
return {
"research_findings": result.data,
"workflow_status": "research_complete"
}
async def write_content(state: ContentCreationState) -> Dict:
"""Writing phase using research findings."""
research = state.research_findings
# Prepare context for writing agent
context = f"""
Topic: {research.topic}
Key Facts:
{chr(10).join(f'- {fact}' for fact in research.key_facts)}
Sources: {', '.join(research.sources)}
Write comprehensive content about this topic.
"""
result = await writing_agent.run(context)
return {
"written_content": result.data,
"workflow_status": "writing_complete"
}
async def fact_check_content(state: ContentCreationState) -> Dict:
"""Fact-checking phase."""
content = state.written_content
research = state.research_findings
# Prepare fact-checking context
check_context = f"""
Original Research Facts:
{chr(10).join(f'- {fact}' for fact in research.key_facts)}
Written Content to Verify:
Title: {content.title}
Introduction: {content.introduction}
Body: {chr(10).join(content.body_paragraphs)}
Verify all claims against the research facts.
"""
result = await fact_check_agent.run(check_context)
return {
"fact_check_report": result.data,
"workflow_status": "fact_check_complete"
}
async def finalize_content(state: ContentCreationState) -> Dict:
"""Final phase - incorporate fact-checking feedback."""
content = state.written_content
fact_check = state.fact_check_report
if fact_check.accuracy_score >= 0.9:
# Content is accurate enough
final = f"{content.title}\n\n{content.introduction}\n\n"
final += "\n\n".join(content.body_paragraphs)
final += f"\n\n{content.conclusion}"
else:
# Need to revise based on fact-checking
revision_agent = Agent(
'openai:gpt-4o',
system_prompt="Revise content to address fact-checking concerns."
)
revision_context = f"""
Original content needs revision.
Corrections needed:
{chr(10).join(f'- {correction}' for correction in fact_check.corrections_needed)}
Original content:
{content.title}
{content.introduction}
{chr(10).join(content.body_paragraphs)}
Revise to ensure accuracy.
"""
revision = await revision_agent.run(revision_context)
final = revision.data
return {
"final_content": final,
"workflow_status": "complete"
}
# Build the multi-agent workflow
def create_content_workflow():
workflow = StateGraph(ContentCreationState)
# Add all nodes
workflow.add_node("research", conduct_research)
workflow.add_node("write", write_content)
workflow.add_node("fact_check", fact_check_content)
workflow.add_node("finalize", finalize_content)
# Define the flow
workflow.set_entry_point("research")
workflow.add_edge("research", "write")
workflow.add_edge("write", "fact_check")
# Conditional edge based on fact-checking results
def route_after_fact_check(state: ContentCreationState) -> str:
if state.fact_check_report.accuracy_score < 0.7:
# Too many errors, go back to research
return "research"
return "finalize"
workflow.add_conditional_edges(
"fact_check",
route_after_fact_check,
{
"research": "research",
"finalize": "finalize"
}
)
workflow.add_edge("finalize", END)
return workflow.compile()
# Use the multi-agent system
content_app = create_content_workflow()
# Create content on any topic
initial_request = ContentCreationState(
user_request="Write about the latest advances in quantum computing"
)
result = await content_app.ainvoke(initial_request)
print(f"Final content:\n{result.final_content}")This multi-agent system showcases several powerful patterns:
- Each agent has a specialized role with its own validation schema
- Data flows between agents are type-safe and validated
- The workflow can loop back if quality checks fail
- The entire system is modular—you can swap agents or add new ones easily
Performance Optimization
Parallel Processing Patterns
When you’re dealing with production workloads, performance becomes critical. Here’s how to optimize your Langgraph + Pydantic AI systems:

Figure 5: Research Platform Architecture – This diagram illustrates a high-performance research platform using parallel processing. Multiple topics are researched simultaneously, with results flowing into a synthesis phase that combines findings.
Let’s implement this high-performance research system:
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from pydantic_ai import Agent
from typing import List, Dict
import asyncio
from concurrent.futures import ThreadPoolExecutor
class TopicResearchTask(BaseModel):
"""Individual research task."""
topic_id: str
topic_name: str
search_queries: List[str]
max_sources: int = 5
class TopicResearchResult(BaseModel):
"""Results from researching a single topic."""
topic_id: str
topic_name: str
findings: List[str]
sources: List[str]
relevance_score: float
class ResearchPlatformState(BaseModel):
"""State for high-performance research platform."""
main_query: str
generated_topics: List[TopicResearchTask] = Field(default_factory=list)
research_results: List[TopicResearchResult] = Field(default_factory=list)
synthesis: Optional[str] = None
performance_metrics: Dict = Field(default_factory=dict)
# Specialized agents
topic_generator = Agent(
'openai:gpt-4o',
system_prompt="""Break down complex research queries into specific,
researchable subtopics. Each topic should be focused and independent."""
)
topic_researcher = Agent(
'openai:gpt-4o',
result_type=TopicResearchResult,
system_prompt="Research the given topic thoroughly and provide structured findings."
)
synthesis_agent = Agent(
'openai:gpt-4o',
system_prompt="""Synthesize multiple research findings into a comprehensive,
coherent report that addresses the original query."""
)
# High-performance workflow implementation
async def generate_research_topics(state: ResearchPlatformState) -> Dict:
"""Generate parallel research topics."""
import time
start_time = time.time()
# Generate topics using the agent
prompt = f"""
Break down this research query into 3-5 independent subtopics:
{state.main_query}
For each topic, provide:
1. A focused topic name
2. 2-3 specific search queries
"""
result = await topic_generator.run(prompt)
# Parse result into structured topics
# In production, you'd have more robust parsing
topics = []
for i in range(3): # Simplified for example
topics.append(TopicResearchTask(
topic_id=f"topic_{i}",
topic_name=f"Subtopic {i+1}",
search_queries=[f"query {i}.1", f"query {i}.2"]
))
generation_time = time.time() - start_time
return {
"generated_topics": topics,
"performance_metrics": {"topic_generation_time": generation_time}
}
async def parallel_research(state: ResearchPlatformState) -> Dict:
"""Research all topics in parallel."""
import time
start_time = time.time()
async def research_single_topic(topic: TopicResearchTask) -> TopicResearchResult:
"""Research a single topic asynchronously."""
# Simulate API calls or database queries
search_results = await asyncio.gather(*[
simulate_search(query) for query in topic.search_queries
])
# Use agent to analyze search results
context = f"""
Topic: {topic.topic_name}
Search Results: {search_results}
Analyze and summarize the findings.
"""
result = await topic_researcher.run(context)
return result.data
# Execute all topic research in parallel
research_tasks = [
research_single_topic(topic) for topic in state.generated_topics
]
results = await asyncio.gather(*research_tasks)
research_time = time.time() - start_time
metrics = state.performance_metrics.copy()
metrics["parallel_research_time"] = research_time
metrics["topics_researched"] = len(results)
return {
"research_results": results,
"performance_metrics": metrics
}
async def synthesize_findings(state: ResearchPlatformState) -> Dict:
"""Synthesize all research into final report."""
# Prepare synthesis context
findings_text = "\n\n".join([
f"Topic: {r.topic_name}\n" +
"\n".join(f"- {finding}" for finding in r.findings)
for r in state.research_results
])
synthesis_prompt = f"""
Original Query: {state.main_query}
Research Findings:
{findings_text}
Create a comprehensive synthesis that addresses the original query.
"""
result = await synthesis_agent.run(synthesis_prompt)
return {"synthesis": result.data}
# Simulate external operations
async def simulate_search(query: str) -> str:
"""Simulate an external search operation."""
await asyncio.sleep(0.1) # Simulate network delay
return f"Results for '{query}'"
# Build the high-performance workflow
def create_research_platform():
workflow = StateGraph(ResearchPlatformState)
workflow.add_node("generate_topics", generate_research_topics)
workflow.add_node("parallel_research", parallel_research)
workflow.add_node("synthesize", synthesize_findings)
workflow.set_entry_point("generate_topics")
workflow.add_edge("generate_topics", "parallel_research")
workflow.add_edge("parallel_research", "synthesize")
workflow.add_edge("synthesize", END)
return workflow.compile()
# Performance monitoring wrapper
async def run_with_monitoring(app, state):
"""Run workflow with performance monitoring."""
import time
start_time = time.time()
result = await app.ainvoke(state)
total_time = time.time() - start_time
print(f"Performance Metrics:")
print(f"- Total execution time: {total_time:.2f}s")
print(f"- Topic generation: {result.performance_metrics['topic_generation_time']:.2f}s")
print(f"- Parallel research: {result.performance_metrics['parallel_research_time']:.2f}s")
print(f"- Topics processed: {result.performance_metrics['topics_researched']}")
print(f"- Speedup vs sequential: {result.performance_metrics['topics_researched']:.1f}x")
return resultOptimization Strategies
Here are key strategies for optimizing your integrated systems:
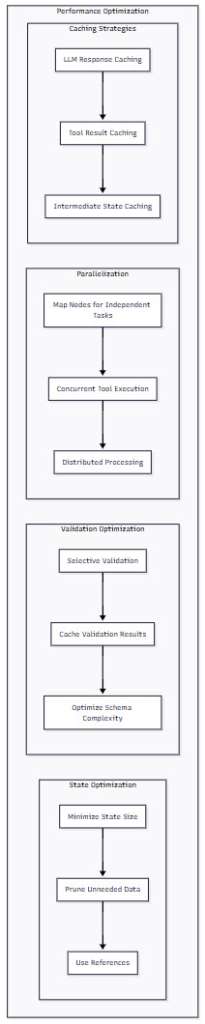
Figure 6: Performance Optimization Strategies – This diagram shows four key areas for optimization: state management, validation efficiency, parallelization opportunities, and caching strategies.
Let’s implement some of these optimization strategies:
from functools import lru_cache
from typing import Dict, Any
import hashlib
import json
class OptimizedWorkflowComponents:
"""Collection of optimization techniques for Langgraph + Pydantic AI."""
def __init__(self):
self.validation_cache = {}
self.llm_response_cache = {}
# 1. State Optimization
def minimize_state(self, state: Dict[str, Any]) -> Dict[str, Any]:
"""Remove unnecessary data from state before transitions."""
# Define fields that need to persist
essential_fields = {'id', 'status', 'current_data', 'next_step'}
# Store large data externally and keep references
minimized = {}
for key, value in state.items():
if key in essential_fields:
minimized[key] = value
elif isinstance(value, (list, dict)) and len(str(value)) > 1000:
# Store large objects externally
ref = self.store_large_object(value)
minimized[f"{key}_ref"] = ref
return minimized
def store_large_object(self, obj: Any) -> str:
"""Store large object and return reference."""
# In production, use S3, Redis, etc.
obj_hash = hashlib.md5(json.dumps(obj, sort_keys=True).encode()).hexdigest()
# Simulate storage
return f"ref://{obj_hash}"
# 2. Validation Optimization
@lru_cache(maxsize=1000)
def cached_validation(self, model_class: type, data_hash: str) -> bool:
"""Cache validation results for repeated data."""
# This would be called with hash of data
# In practice, implement actual validation
return True
# 3. Parallel Agent Execution
async def parallel_agent_calls(self, agents: List[Agent], prompts: List[str]) -> List[Any]:
"""Execute multiple agents in parallel."""
tasks = [
agent.run(prompt)
for agent, prompt in zip(agents, prompts)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
# Handle any failures
processed_results = []
for i, result in enumerate(results):
if isinstance(result, Exception):
# Fallback or retry logic
processed_results.append(None)
else:
processed_results.append(result.data)
return processed_results
# 4. Response Caching
def get_cached_response(self, agent_id: str, prompt: str) -> Optional[str]:
"""Check if we have a cached response for this prompt."""
cache_key = f"{agent_id}:{hashlib.md5(prompt.encode()).hexdigest()}"
return self.llm_response_cache.get(cache_key)
def cache_response(self, agent_id: str, prompt: str, response: str):
"""Cache an LLM response."""
cache_key = f"{agent_id}:{hashlib.md5(prompt.encode()).hexdigest()}"
self.llm_response_cache[cache_key] = response
# Example: Optimized document processing workflow
class OptimizedDocumentProcessor:
"""Document processor with performance optimizations."""
def __init__(self):
self.optimizer = OptimizedWorkflowComponents()
self.summary_agent = Agent(
'openai:gpt-3.5-turbo', # Cheaper, faster model
system_prompt="Summarize documents concisely."
)
self.analysis_agent = Agent(
'openai:gpt-4o', # More capable model for complex analysis
system_prompt="Provide deep analysis of document content."
)
async def process_documents_batch(self, documents: List[str]) -> Dict:
"""Process multiple documents with optimizations."""
# 1. Use cheaper model for initial filtering
summaries = await self.optimizer.parallel_agent_calls(
[self.summary_agent] * len(documents),
[f"Summarize: {doc[:500]}" for doc in documents] # Only send first 500 chars
)
# 2. Filter documents that need deep analysis
documents_for_analysis = []
for i, (doc, summary) in enumerate(zip(documents, summaries)):
if self.needs_deep_analysis(summary):
documents_for_analysis.append((i, doc))
# 3. Parallel deep analysis only for selected documents
if documents_for_analysis:
analysis_prompts = [
f"Analyze this document in detail: {doc}"
for _, doc in documents_for_analysis
]
analyses = await self.optimizer.parallel_agent_calls(
[self.analysis_agent] * len(documents_for_analysis),
analysis_prompts
)
# 4. Combine results
results = {
"total_documents": len(documents),
"analyzed_documents": len(documents_for_analysis),
"summaries": summaries,
"detailed_analyses": {
i: analysis
for (i, _), analysis in zip(documents_for_analysis, analyses)
}
}
return results
def needs_deep_analysis(self, summary: str) -> bool:
"""Determine if document needs deep analysis based on summary."""
# Simple heuristic - in practice, use more sophisticated logic
keywords = ['important', 'critical', 'urgent', 'complex']
return any(keyword in summary.lower() for keyword in keywords)Real-World Applications
E-commerce Order Processing
Let’s look at how this technology stack powers real-world applications. Here’s an e-commerce order processing system that handles everything from validation to fulfillment:
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field, validator
from pydantic_ai import Agent
from typing import List, Optional, Literal
from datetime import datetime
from decimal import Decimal
# Domain models
class OrderItem(BaseModel):
"""Individual item in an order."""
product_id: str
quantity: int = Field(gt=0)
unit_price: Decimal = Field(gt=0, decimal_places=2)
@property
def total_price(self) -> Decimal:
return self.quantity * self.unit_price
class Order(BaseModel):
"""E-commerce order with validation."""
order_id: str
customer_id: str
items: List[OrderItem] = Field(min_items=1)
shipping_address: str
billing_address: str
payment_method: Literal["credit_card", "paypal", "bank_transfer"]
status: str = "pending"
@property
def total_amount(self) -> Decimal:
return sum(item.total_price for item in self.items)
@validator('items')
def validate_items(cls, items):
# Check for duplicate products
product_ids = [item.product_id for item in items]
if len(product_ids) != len(set(product_ids)):
raise ValueError("Duplicate products in order")
return items
class OrderProcessingState(BaseModel):
"""State for order processing workflow."""
order: Order
inventory_checked: bool = False
payment_verified: bool = False
shipping_arranged: bool = False
notifications_sent: List[str] = Field(default_factory=list)
processing_errors: List[str] = Field(default_factory=list)
# Specialized agents
inventory_agent = Agent(
'openai:gpt-4o',
system_prompt="""You are an inventory management specialist.
Check product availability and reserve items."""
)
payment_agent = Agent(
'openai:gpt-4o',
system_prompt="""You are a payment processing specialist.
Verify payment methods and process transactions securely."""
)
shipping_agent = Agent(
'openai:gpt-4o',
system_prompt="""You are a shipping coordinator.
Arrange optimal shipping based on destination and items."""
)
# Workflow implementation
async def check_inventory(state: OrderProcessingState) -> Dict:
"""Check inventory for all items."""
# In production, this would query real inventory systems
inventory_query = "\n".join([
f"Product {item.product_id}: {item.quantity} units"
for item in state.order.items
])
result = await inventory_agent.run(
f"Check availability for:\n{inventory_query}"
)
# Simulate inventory check
all_available = True # In reality, parse agent response
if all_available:
return {
"inventory_checked": True,
"order": {**state.order.dict(), "status": "inventory_confirmed"}
}
else:
return {
"processing_errors": state.processing_errors + ["Insufficient inventory"],
"order": {**state.order.dict(), "status": "failed"}
}
async def process_payment(state: OrderProcessingState) -> Dict:
"""Process payment for the order."""
if not state.inventory_checked:
return {
"processing_errors": state.processing_errors + ["Cannot process payment before inventory check"]
}
payment_context = f"""
Order Total: ${state.order.total_amount}
Payment Method: {state.order.payment_method}
Customer ID: {state.order.customer_id}
"""
result = await payment_agent.run(
f"Process payment:\n{payment_context}"
)
# Simulate payment processing
payment_successful = True # In reality, integrate with payment gateway
if payment_successful:
return {
"payment_verified": True,
"order": {**state.order.dict(), "status": "payment_confirmed"},
"notifications_sent": state.notifications_sent + ["payment_confirmation"]
}
else:
return {
"processing_errors": state.processing_errors + ["Payment failed"],
"order": {**state.order.dict(), "status": "payment_failed"}
}
async def arrange_shipping(state: OrderProcessingState) -> Dict:
"""Arrange shipping for the order."""
if not state.payment_verified:
return {
"processing_errors": state.processing_errors + ["Cannot ship before payment"]
}
shipping_context = f"""
Destination: {state.order.shipping_address}
Items: {len(state.order.items)} items, Total weight: TBD
Priority: Standard
"""
result = await shipping_agent.run(
f"Arrange shipping:\n{shipping_context}"
)
return {
"shipping_arranged": True,
"order": {**state.order.dict(), "status": "shipped"},
"notifications_sent": state.notifications_sent + ["shipping_confirmation"]
}
# Build the order processing workflow
def create_order_workflow():
workflow = StateGraph(OrderProcessingState)
workflow.add_node("inventory", check_inventory)
workflow.add_node("payment", process_payment)
workflow.add_node("shipping", arrange_shipping)
# Define flow with conditional routing
workflow.set_entry_point("inventory")
def route_after_inventory(state: OrderProcessingState) -> str:
if state.inventory_checked and not state.processing_errors:
return "payment"
return END
def route_after_payment(state: OrderProcessingState) -> str:
if state.payment_verified and not state.processing_errors:
return "shipping"
return END
workflow.add_conditional_edges("inventory", route_after_inventory)
workflow.add_conditional_edges("payment", route_after_payment)
workflow.add_edge("shipping", END)
return workflow.compile()
# Usage example
order_processor = create_order_workflow()
# Process an order
test_order = Order(
order_id="ORD-12345",
customer_id="CUST-789",
items=[
OrderItem(product_id="PROD-A", quantity=2, unit_price=Decimal("29.99")),
OrderItem(product_id="PROD-B", quantity=1, unit_price=Decimal("49.99"))
],
shipping_address="123 Main St, Anytown, USA",
billing_address="123 Main St, Anytown, USA",
payment_method="credit_card"
)
initial_state = OrderProcessingState(order=test_order)
result = await order_processor.ainvoke(initial_state)
print(f"Order Status: {result.order.status}")
print(f"Notifications sent: {result.notifications_sent}")This real-world example shows how Langgraph and Pydantic AI handle:
- Complex business logic with multiple steps
- Validation at every stage
- Conditional routing based on success/failure
- Integration points for external systems
- Comprehensive error handling
Benefits and Challenges
Advantages of the Integrated Approach
After building several production systems with Langgraph and Pydantic AI, the benefits are clear:
Workflow Flexibility: Langgraph’s graph-based approach lets you model complex, real-world workflows naturally. Need to add a fraud check step? Just add a node. Want parallel processing? Add parallel edges.
Type Safety Throughout: Pydantic’s validation ensures data integrity at every step. You’re not hoping the LLM returns the right format—you’re guaranteeing it.
Improved Debugging: When something goes wrong, you can see exactly which node failed and why. The combination of structured logs and validated data makes debugging almost pleasant.
Reusability: Both frameworks encourage modular design. Agents can be reused across workflows, and workflow patterns can be templated for similar use cases.
Scalability: The graph structure naturally supports horizontal scaling. Different nodes can run on different machines, and the state management keeps everything coordinated.
Challenges and Solutions
Let’s be honest about the challenges too:
Learning Curve: If you’re coming from simple LLM chains, the graph-based thinking requires adjustment. Start with simple linear workflows and gradually add complexity.
State Management Complexity: As workflows grow, managing state becomes challenging. Use the checkpointing features and external storage for large data.
Performance Overhead: Validation and state management add latency. Profile your workflows and optimize critical paths with caching and parallelization.
Testing Complexity: Testing stateful workflows is harder than testing individual functions. Build comprehensive test suites that cover both happy paths and edge cases.
Future Directions
Emerging Patterns
The field is evolving rapidly, and we’re seeing exciting developments:
Adaptive Workflows: Systems that modify their own graphs based on performance metrics or user feedback.
Cross-Organization Workflows: Federated graphs that span multiple organizations while maintaining security and privacy.
Real-time Collaboration: Multiple agents and humans working together in the same workflow with live state updates.
Advanced State Persistence: More sophisticated checkpointing with automatic recovery and migration capabilities.
Practical Takeaways
If you’re ready to build production AI systems with Langgraph and Pydantic AI, here are my recommendations:
Start with a clear workflow diagram: Before writing code, sketch out your workflow as a graph. Identify nodes, edges, and state requirements.
Define your data models first: Use Pydantic to create comprehensive models for all data flowing through your system. This investment pays off quickly.
Build incrementally: Start with a simple linear workflow and add complexity gradually. Each addition should be tested thoroughly.
Implement comprehensive monitoring: Track not just errors but also performance metrics, state transitions, and agent interactions.
Plan for failure: Design your workflows with error handling from the start. Use conditional edges to handle failures gracefully.
Conclusion
The combination of Langgraph and Pydantic AI represents a paradigm shift in how we build AI agent systems. By bringing together flexible orchestration and strict validation, we can create applications that are both powerful and reliable—no longer forced to choose between innovation and stability.
As AI systems become more complex and mission-critical, the patterns we’ve explored here will become essential. The ability to model sophisticated workflows while maintaining data integrity isn’t just nice to have—it’s the foundation of production-ready AI applications.
The future of AI development isn’t just about better models or cleverer prompts. It’s about building robust systems that can handle the complexity of real-world problems while maintaining the reliability that businesses demand. With Langgraph and Pydantic AI, we finally have the tools to make that future a reality.
References
[1] “Langgraph: A Comprehensive Technical Overview.” https://github.com/langchain-ai/langgraph (2025)[2] “Pydantic AI: An Agent Framework for Building GenAI Applications.” https://github.com/jxnl/pydantic-ai (2025)
[3] “Best Practices for Designing Multi-Agent Systems with LangGraph.” https://blog.langchain.dev/multi-agent-systems/ (2025)
[4] “Integrating Langgraph with Pydantic: Validation Patterns for State Transitions.” https://docs.pydantic.ai/latest/integrations/ (2025)
[5] “Error Handling in Langgraph: From Validation to Graceful Recovery.” https://python.langchain.com/docs/langgraph/error-handling/ (2025)
[6] “Performance Considerations for Scaling LangGraph + Pydantic AI Systems.” https://docs.pydantic.ai/latest/usage/pydantic_ai/ (2025)
[7] “Exploring Pydantic AI’s Core Features: Schema Inference, Function Calling, and Structured Output.” https://jxnl.github.io/instructor/ (2024)
[8] “Technical Benefits of Pydantic AI for Implementing AI Agent Patterns.” https://medium.com/@pydantic/pydantic-ai-9c211c5dfa5 (2024)
[9] “Pydantic AI in Production: Agent Patterns, Challenges, and Benefits.” https://www.pydantic.dev/blog/pydantic-ai-in-production/ (2025)
