Share This Article
In the rapidly evolving landscape of AI development, we’re witnessing an explosion of large language model (LLM) applications that promise to revolutionize how we work. Yet beneath the surface of this excitement lies a harsh reality: most LLM applications in production are brittle, unpredictable, and frustratingly difficult to maintain. Traditional approaches often result in tangled codebases where prompts, validation logic, and tool integrations become so intertwined that even simple changes risk breaking the entire system.

As AI practitioners, we’ve all experienced the pain of debugging an LLM application where responses occasionally go off the rails, tool calls fail silently, or the model confidently produces outputs that violate basic business rules. The problem isn’t the models themselves—it’s that we’re building on foundations of sand, lacking the structured patterns and type safety that we take for granted in traditional software development.
This is where the convergence of two powerful concepts changes everything: Anthropic’s agent blueprint patterns and Pydantic AI’s type-safe framework. By combining battle-tested agent architectures with robust data validation, we can finally build LLM applications that are both powerful and predictable. Think of it as bringing software engineering discipline to the wild west of AI development.
In this article, we’ll dive into:
- Understanding AI agents and the crucial distinction between workflows and autonomous agents
- The technical architecture that makes reliable AI agent systems possible
- Five foundational and advanced patterns from Anthropic’s agent blueprint
- Practical Pydantic AI implementations with production-ready code examples
- Testing strategies, monitoring approaches, and deployment considerations
- Real-world benefits, limitations, and future directions of structured agent frameworks
- Hands-on examples you can adapt for your own projects
Understanding AI Agents
What Are AI Agents?
Let’s start with a fundamental question: what exactly makes something an “AI agent” rather than just another LLM application? AI agents are systems that go beyond simple prompt-response interactions. They maintain state, make decisions based on context, and can engage in multi-step reasoning processes to achieve specific goals. You can think of them as LLMs with agency—the ability to decide not just what to say, but what to do next.
The key insight here is that agents aren’t just about generating text. They’re about orchestrating complex workflows, interacting with external tools, and maintaining coherent behavior across extended interactions. When you ask ChatGPT a question, you’re using an LLM. When that LLM can search the web, run calculations, and remember previous context to solve a complex problem, you’re working with an agent.
The Agent vs. Workflow Distinction
Here’s where things get interesting. Anthropic makes a crucial distinction that many developers miss: not everything needs to be an agent. In fact, there’s a spectrum between two fundamental approaches:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths. Think of them like a recipe—you know exactly what steps will happen and in what order. The LLM might generate content or make simple decisions, but the overall flow is determined by your code. These systems are predictable, debuggable, and perfect for many real-world applications.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage. The model itself decides what to do next based on the context and available tools. This offers incredible flexibility but comes with the cost of less predictability.
As Adam Elkus from Anthropic puts it: “The workflow/agent distinction is less a binary and more a spectrum of giving the model increasing autonomy in directing computation” [1]. This insight is liberating—you don’t have to go full autonomous agent for every use case. Often, a workflow with some agent-like capabilities hits the sweet spot.
The Augmented LLM Model
At the heart of both workflows and agents is what we call the augmented LLM. This isn’t just a raw language model—it’s an LLM enhanced with additional capabilities:
- Base Language Model: The foundation that provides reasoning and text generation
- Tools: Functions the model can call to interact with external systems
- Structured Output: Validation that ensures responses follow expected formats
- Memory: Context management across multiple interactions
- Retrieval: Access to external knowledge bases
These augmentations transform a simple text generator into a system capable of solving real problems. And this is where Pydantic AI shines—it provides the framework to implement these augmentations reliably.
AI Agents vs. Traditional Frameworks
To really grasp why agent frameworks matter, let’s compare them with traditional application development approaches:
| Feature | Traditional Frameworks | AI Agent Frameworks |
|---|---|---|
| Control Flow | Static, predefined paths | Dynamic, model-driven decisions |
| Data Handling | Strict types, rigid schemas | Flexible schemas with validation |
| Error Recovery | Exception handling | Self-correction and retry mechanisms |
| Integration Pattern | Direct API calls | Tool-based abstractions |
| Decision Making | Rule-based logic | Natural language reasoning |
| Maintenance | Code changes required | Can adapt through prompts |
The magic happens when you combine the best of both worlds: the flexibility of AI agents with the reliability of traditional software engineering practices. That’s exactly what we’re going to explore.
The Technical Architecture Behind AI Agents
The Pydantic AI Framework
Pydantic AI isn’t just another LLM wrapper—it’s a thoughtfully designed framework that brings type safety and structure to agent development. Building on the robust validation capabilities of Pydantic (which you might know from FastAPI), it extends these concepts specifically for AI agents.
The architecture consists of four essential layers, each serving a specific purpose:
Model Layer
This layer abstracts away the differences between LLM providers. Whether you’re using OpenAI, Anthropic, or Google’s models, Pydantic AI provides a consistent interface. More importantly, it handles all the messy details of prompt construction, message formatting, and response parsing that typically lead to bugs.
Validation Layer
The heart of Pydantic AI lives here. Every input and output can be validated against schemas you define, catching errors before they propagate through your system. This isn’t just about type checking—it’s about ensuring that your agent’s outputs make sense in your domain.
Tool Layer
Tools are what transform an LLM from a chatbot into an agent. This layer provides a clean abstraction for defining functions your agent can call, complete with parameter validation and result handling. No more string manipulation to parse tool calls!
Agent Layer
The highest level brings it all together, implementing the patterns that orchestrate models, tools, and validation into coherent agent behaviors. This is where you’ll spend most of your time, building on the solid foundation below.
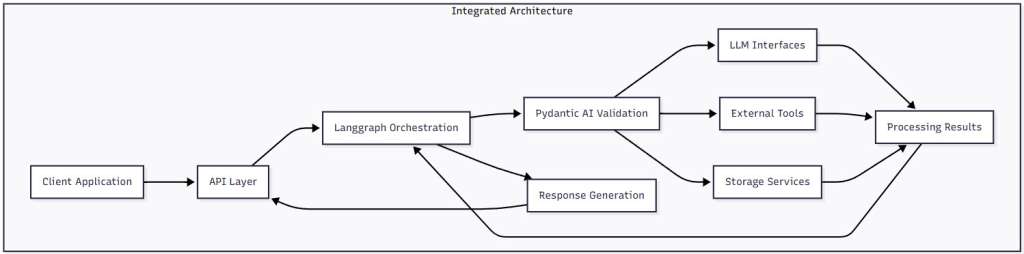
Figure 1: Pydantic AI Architecture – This diagram illustrates the four-layer architecture of Pydantic AI, showing how each layer builds upon the previous one to create a complete agent framework. Notice how data flows from the Model Layer through Validation and Tools, ultimately orchestrated by the Agent Layer.
Agent Patterns and Execution Flow
Understanding how agents execute is crucial for building reliable systems. Here’s the typical flow:
- Initialization: Configure your agent with a model, system prompt, and available tools
- Input Processing: Receive and preprocess user input
- Context Building: Combine input with relevant history and system prompts
- LLM Invocation: Send the formatted context to the language model
- Tool Execution: If the LLM requests tool usage, execute the appropriate functions
- Response Validation: Ensure the output conforms to your expected schema
- Output Generation: Return the validated response to the user
What makes this powerful is that each step can be customized, validated, and monitored. You’re not just hoping the LLM does the right thing—you’re guiding it with guardrails at every step.
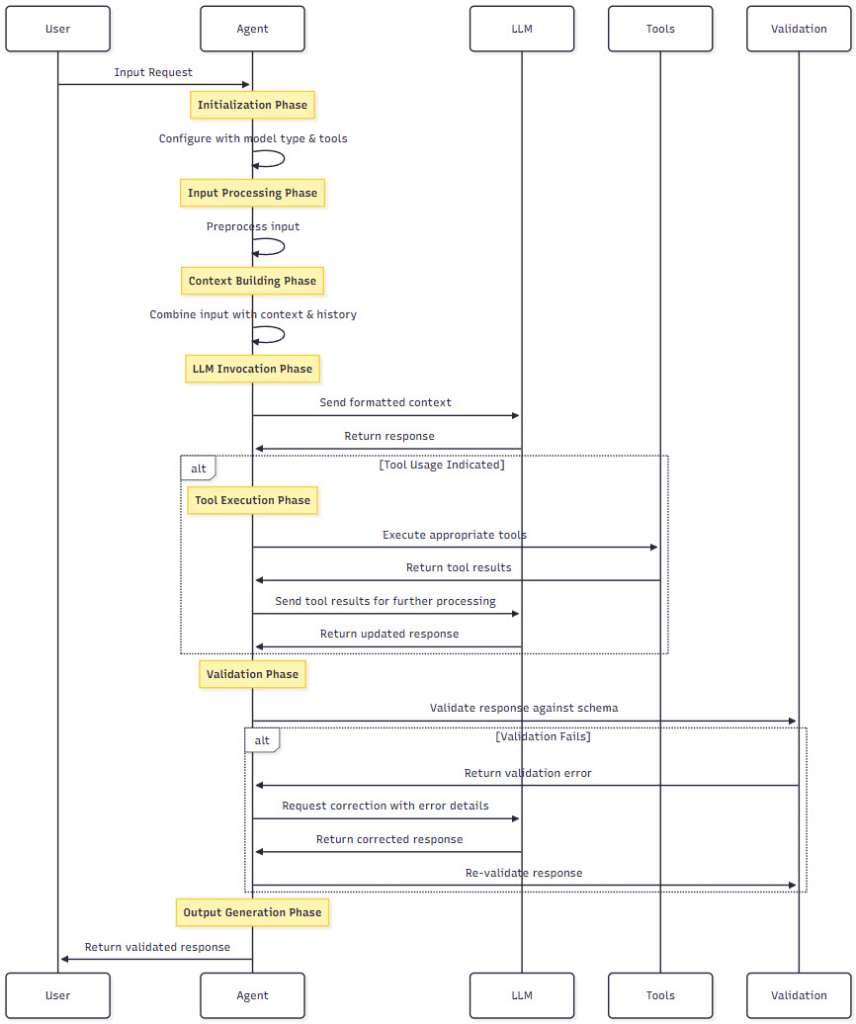
Figure 2: Agent Execution Flow – This diagram shows the step-by-step execution flow of a Pydantic AI agent, from receiving user input to generating a validated response. Each step includes validation checkpoints to ensure reliability.
Five Essential Patterns for AI Agents
Now let’s dive into the meat of Anthropic’s agent blueprint. These patterns aren’t just theoretical—they’re battle-tested approaches that solve real problems. We’ll implement each one with Pydantic AI to show you exactly how they work.
1. Prompt Chaining
Prompt chaining is the workhorse pattern of agent development. Instead of trying to solve complex problems in one shot, you break them down into a sequence of simpler steps. Each step focuses on one specific transformation, making the overall process more reliable and debuggable.
Think of it like an assembly line—each station has one job and does it well. This approach is perfect when you can decompose a task into clear, sequential steps.
from pydantic import BaseModel, Field
from typing import List, Optional
from pydantic_ai import Agent
class ChainStep(BaseModel):
"""Represents a single step in our prompt chain."""
prompt_template: str = Field(..., description="Template for the prompt, with {input} placeholder")
name: str = Field(..., description="Name of this step for debugging")
validation_rules: Optional[List[str]] = Field(None, description="Rules to validate the output")
class PromptChain:
"""Executes a sequence of prompts, passing output from each to the next."""
def __init__(self, steps: List[ChainStep], model_type: str = "openai:gpt-4o"):
self.steps = steps
self.agent = Agent(model_type)
async def execute(self, input_data: str) -> str:
"""Execute the chain on the input data."""
result = input_data
for step in self.steps:
# Format the prompt with the previous result
prompt = step.prompt_template.format(input=result)
# Call the LLM using Pydantic AI
response = await self.agent.run(prompt)
result = response.data
# Validate if rules are specified
if step.validation_rules:
self._validate_output(result, step.validation_rules)
return result
def _validate_output(self, output: str, rules: List[str]):
"""Apply validation rules to the output."""
# Implementation depends on your specific rules
pass
# Example: Building a research summarization chain
research_chain = PromptChain([
ChainStep(
name="extract_key_points",
prompt_template="Extract the key points from this text: {input}"
),
ChainStep(
name="organize_themes",
prompt_template="Organize these key points into themes: {input}"
),
ChainStep(
name="write_summary",
prompt_template="Write a concise summary based on these themes: {input}"
)
])
</code>The beauty of this pattern is its simplicity and debuggability. If something goes wrong, you can inspect the output at each step. Need to improve quality? You can optimize individual steps without affecting the others.
2. Routing
Not all problems follow a linear path. The routing pattern lets your agent intelligently direct queries to specialized handlers based on the input type. It’s like having a smart receptionist who knows exactly which department can best help each visitor.
from pydantic import BaseModel, Field
from typing import Dict, Optional
from pydantic_ai import Agent
class RouteRequest(BaseModel):
"""Input request that needs routing."""
query: str = Field(..., description="The user query to classify and route")
context: Optional[Dict] = Field(None, description="Additional context for routing decisions")
class RouteResponse(BaseModel):
"""Routing decision from our classifier."""
route: str = Field(..., description="Selected route identifier")
confidence: float = Field(..., ge=0, le=1, description="Confidence in this routing decision")
reasoning: str = Field(..., description="Explanation for the routing choice")
class Router:
"""Intelligently routes queries to specialized handlers."""
def __init__(self, classifier_prompt: str, handlers: Dict[str, Agent]):
self.classifier_prompt = classifier_prompt
self.handlers = handlers
# Use a structured output type for reliable routing decisions
self.classifier = Agent(
'anthropic:claude-3-sonnet-20240229',
result_type=RouteResponse
)
async def route_and_process(self, request: RouteRequest) -> str:
"""Classify the request and route to appropriate handler."""
# Build a description of available routes
routes_desc = "\n".join([
f"- {route_id}: {handler.system_prompt[:50]}..."
for route_id, handler in self.handlers.items()
])
# Classify the request
prompt = self.classifier_prompt.format(
query=request.query,
available_routes=routes_desc,
**request.context or {}
)
route_response = await self.classifier.run(prompt)
# Handle unknown routes gracefully
handler = self.handlers.get(route_response.data.route)
if not handler:
return f"I'm not sure how to handle that. Routing confidence was {route_response.data.confidence}"
# Process with the specialized handler
result = await handler.run(request.query)
return result.data
# Example: Customer support router
support_router = Router(
classifier_prompt="""Classify this customer query and select the best handler:
Query: {query}
Available handlers:
{available_routes}
Select the most appropriate handler based on the query type.""",
handlers={
"technical": Agent("openai:gpt-4o", system_prompt="You are a technical support specialist..."),
"billing": Agent("openai:gpt-4o", system_prompt="You are a billing support agent..."),
"general": Agent("openai:gpt-4o", system_prompt="You are a friendly customer service agent...")
}
)
</code>What I love about this pattern is how it scales. As your application grows, you can add new specialized handlers without touching the existing ones. The router ensures each query gets expert treatment.
3. Parallelization
When faced with tasks that can be decomposed into independent subtasks, parallelization can dramatically improve both performance and quality. This pattern comes in two flavors:
- Sectioning: Breaking a task into parts that can be processed simultaneously
- Voting: Running the same task multiple times to get diverse perspectives
from pydantic import BaseModel, Field
from typing import List, Dict, Any
from pydantic_ai import Agent
import asyncio
class SectioningTask(BaseModel):
"""A subtask that can be processed independently."""
section_id: str = Field(..., description="Unique identifier for this section")
prompt_template: str = Field(..., description="Prompt template for processing this section")
data: Dict[str, Any] = Field(default_factory=dict, description="Section-specific data")
class ParallelExecutor:
"""Execute tasks in parallel for improved performance."""
def __init__(self, model_type: str = "openai:gpt-4o"):
self.model_type = model_type
async def execute_sectioning(self, tasks: List[SectioningTask], shared_data: Dict[str, Any] = None) -> Dict[str, str]:
"""Process multiple sections in parallel."""
shared_data = shared_data or {}
async def process_section(task):
# Create an agent for this section
agent = Agent(self.model_type)
# Combine shared and section-specific data
prompt = task.prompt_template.format(**{**shared_data, **task.data})
# Process asynchronously
result = await agent.run(prompt)
return task.section_id, result.data
# Execute all sections concurrently
coroutines = [process_section(task) for task in tasks]
results_list = await asyncio.gather(*coroutines)
# Convert to dictionary for easy access
return {section_id: result for section_id, result in results_list}
async def execute_voting(self, prompt: str, num_votes: int = 3) -> Dict[str, Any]:
"""Get multiple perspectives on the same prompt."""
async def get_vote(vote_num):
agent = Agent(self.model_type, system_prompt=f"You are assistant {vote_num}. Provide your perspective.")
result = await agent.run(prompt)
return result.data
# Collect all votes
votes = await asyncio.gather(*[get_vote(i) for i in range(num_votes)])
# Analyze consensus (simplified example)
return {
"votes": votes,
"consensus": self._find_consensus(votes)
}
def _find_consensus(self, votes: List[str]) -> str:
"""Analyze votes to find consensus (simplified)."""
# In practice, you might use another LLM call or more sophisticated analysis
return "Majority opinion: " + votes[0] # Placeholder
# Example: Parallel document analysis
async def analyze_document(document: str):
executor = ParallelExecutor()
# Split into sections for parallel processing
tasks = [
SectioningTask(
section_id="summary",
prompt_template="Summarize this document: {document}",
data={"document": document}
),
SectioningTask(
section_id="key_points",
prompt_template="Extract key points from: {document}",
data={"document": document}
),
SectioningTask(
section_id="sentiment",
prompt_template="Analyze the sentiment of: {document}",
data={"document": document}
)
]
results = await executor.execute_sectioning(tasks)
return results
</code>This pattern shines when you have tasks that would take too long sequentially or when you want multiple perspectives to improve quality. The key is identifying truly independent subtasks.
4. Orchestrator-Workers
The orchestrator-workers pattern is where things get really interesting. Instead of predefined workflows, you have a central LLM that dynamically breaks down tasks and coordinates specialized workers. It’s like having a project manager who understands the problem and delegates to the right team members.
from pydantic import BaseModel, Field
from typing import List, Dict, Any
from pydantic_ai import Agent
class SubTask(BaseModel):
"""A subtask created by the orchestrator."""
task_id: str = Field(..., description="Unique identifier")
type: str = Field(..., description="Type of subtask - determines which worker to use")
description: str = Field(..., description="What needs to be done")
dependencies: List[str] = Field(default_factory=list, description="IDs of tasks this depends on")
context: Dict[str, Any] = Field(default_factory=dict, description="Additional context for the worker")
class TaskDecomposition(BaseModel):
"""The orchestrator's plan for solving a complex task."""
subtasks: List[SubTask]
execution_order: List[str] = Field(..., description="Suggested order of execution")
class OrchestratorSystem:
"""Dynamic task decomposition and execution system."""
def __init__(
self,
orchestrator_prompt: str,
worker_prompts: Dict[str, str],
orchestrator_model: str = "anthropic:claude-3-opus-20240229",
worker_model: str = "openai:gpt-4o"
):
self.orchestrator_prompt = orchestrator_prompt
self.worker_prompts = worker_prompts
# Orchestrator with structured output for reliable task decomposition
self.orchestrator = Agent(
orchestrator_model,
result_type=TaskDecomposition,
system_prompt="You are a task orchestrator. Break down complex tasks into manageable subtasks."
)
self.worker_model = worker_model
self.completed_tasks = {}
async def process_task(self, task: str, context: Dict[str, Any] = None) -> Dict[str, Any]:
"""Process a complex task through orchestration."""
context = context or {}
# Step 1: Decompose the task
decompose_prompt = self.orchestrator_prompt.format(
task=task,
available_workers=list(self.worker_prompts.keys()),
**context
)
decomposition = await self.orchestrator.run(decompose_prompt)
subtasks = decomposition.data.subtasks
# Step 2: Execute subtasks respecting dependencies
results = {}
for subtask in self._order_by_dependencies(subtasks):
# Wait for dependencies
await self._wait_for_dependencies(subtask, results)
# Execute subtask
worker_result = await self._execute_subtask(subtask, results)
results[subtask.task_id] = worker_result
# Step 3: Synthesize results
synthesis_result = await self._synthesize_results(task, subtasks, results)
return {
"task": task,
"subtasks": [st.dict() for st in subtasks],
"results": results,
"final_result": synthesis_result
}
async def _execute_subtask(self, subtask: SubTask, completed_results: Dict[str, Any]) -> str:
"""Execute a single subtask with the appropriate worker."""
worker_prompt = self.worker_prompts.get(subtask.type)
if not worker_prompt:
return f"No worker available for task type: {subtask.type}"
# Create context including dependency results
context = {
"description": subtask.description,
"dependencies": {dep_id: completed_results.get(dep_id) for dep_id in subtask.dependencies},
**subtask.context
}
worker = Agent(
self.worker_model,
system_prompt=worker_prompt
)
result = await worker.run(str(context))
return result.data
def _order_by_dependencies(self, subtasks: List[SubTask]) -> List[SubTask]:
"""Order subtasks respecting dependencies (simplified topological sort)."""
# In practice, implement proper topological sorting
return sorted(subtasks, key=lambda x: len(x.dependencies))
async def _wait_for_dependencies(self, subtask: SubTask, results: Dict[str, Any]):
"""Wait for all dependencies to complete."""
# In a real implementation, this would handle async coordination
pass
async def _synthesize_results(self, original_task: str, subtasks: List[SubTask], results: Dict[str, Any]) -> str:
"""Combine all results into a final answer."""
synthesis_agent = Agent(
self.orchestrator.model_name,
system_prompt="You are a synthesis expert. Combine subtask results into a coherent final answer."
)
synthesis_prompt = f"""
Original task: {original_task}
Completed subtasks and results:
{self._format_results_for_synthesis(subtasks, results)}
Synthesize these results into a comprehensive final solution.
"""
final_result = await synthesis_agent.run(synthesis_prompt)
return final_result.data
def _format_results_for_synthesis(self, subtasks: List[SubTask], results: Dict[str, Any]) -> str:
"""Format results for the synthesis step."""
formatted = []
for subtask in subtasks:
result = results.get(subtask.task_id, "No result")
formatted.append(f"- {subtask.description}: {result}")
return "\n".join(formatted)
# Example: Research orchestrator
research_orchestrator = OrchestratorSystem(
orchestrator_prompt="""Break down this research task into subtasks:
Task: {task}
Available workers: {available_workers}
Create a plan with specific subtasks that can be executed by the available workers.""",
worker_prompts={
"search": "You are a search specialist. Find relevant information based on the given query.",
"analyze": "You are an analysis expert. Analyze the provided information and extract insights.",
"synthesize": "You are a synthesis specialist. Combine multiple pieces of information coherently.",
"fact_check": "You are a fact checker. Verify the accuracy of the provided claims."
}
)
</code>This pattern is incredibly powerful for complex, open-ended tasks where you can’t predict all the steps in advance. The orchestrator acts like a junior developer who breaks down requirements and delegates to specialists.
5. Evaluator-Optimizer
The evaluator-optimizer pattern creates a feedback loop where one LLM generates content and another critiques it, leading to iterative improvement. It’s like having a writer and an editor working together, each cycle producing better results.
from pydantic import BaseModel, Field
from typing import List, Dict, Literal
from pydantic_ai import Agent
class EvaluationCriteria(BaseModel):
"""Criteria for evaluating generated content."""
name: str = Field(..., description="Name of this criterion")
description: str = Field(..., description="What this criterion measures")
threshold: float = Field(..., ge=0, le=1, description="Minimum score to pass")
weight: float = Field(1.0, description="Importance weight for this criterion")
class Evaluation(BaseModel):
"""Structured evaluation of generated content."""
status: Literal["PASS", "NEEDS_IMPROVEMENT", "FAIL"] = Field(..., description="Overall status")
criteria_scores: Dict[str, float] = Field(..., description="Individual criterion scores")
feedback: str = Field(..., description="Specific, actionable feedback for improvement")
strengths: List[str] = Field(default_factory=list, description="What worked well")
improvements: List[str] = Field(default_factory=list, description="Specific improvements needed")
@property
def passed(self) -> bool:
"""Check if the evaluation passed all criteria."""
return self.status == "PASS"
@property
def overall_score(self) -> float:
"""Calculate weighted overall score."""
if not self.criteria_scores:
return 0.0
return sum(score for score in self.criteria_scores.values()) / len(self.criteria_scores)
class EvaluatorOptimizerSystem:
"""Iterative improvement through evaluation and optimization."""
def __init__(
self,
optimizer_prompt: str,
evaluator_prompt: str,
criteria: List[EvaluationCriteria],
max_iterations: int = 5,
optimizer_model: str = "openai:gpt-4o",
evaluator_model: str = "anthropic:claude-3-sonnet-20240229"
):
self.optimizer_prompt = optimizer_prompt
self.evaluator_prompt = evaluator_prompt
self.criteria = criteria
self.max_iterations = max_iterations
# Different models for different strengths
self.optimizer = Agent(optimizer_model, system_prompt="You are a content creator focused on quality.")
self.evaluator = Agent(
evaluator_model,
result_type=Evaluation,
system_prompt="You are a critical evaluator. Provide honest, constructive feedback."
)
async def optimize(self, task: str, context: Dict[str, str] = None) -> Dict[str, Any]:
"""Run the optimization loop."""
context = context or {}
history = []
# Initial generation
content = await self._generate_initial(task, context)
for iteration in range(self.max_iterations):
# Evaluate current content
evaluation = await self._evaluate_content(task, content, context)
# Track history
history.append({
"iteration": iteration,
"content": content,
"evaluation": evaluation.dict(),
"score": evaluation.overall_score
})
# Check if we're done
if evaluation.passed:
break
# Generate improved version
content = await self._improve_content(task, content, evaluation, context)
return {
"task": task,
"final_content": content,
"iterations": len(history),
"passed": evaluation.passed,
"final_score": evaluation.overall_score,
"history": history
}
async def _generate_initial(self, task: str, context: Dict[str, str]) -> str:
"""Generate the initial content."""
prompt = self.optimizer_prompt.format(
task=task,
**context
)
response = await self.optimizer.run(prompt)
return response.data
async def _evaluate_content(self, task: str, content: str, context: Dict[str, str]) -> Evaluation:
"""Evaluate content against criteria."""
criteria_text = "\n".join([
f"- {c.name}: {c.description} (minimum score: {c.threshold})"
for c in self.criteria
])
prompt = self.evaluator_prompt.format(
task=task,
content=content,
criteria=criteria_text,
**context
)
response = await self.evaluator.run(prompt)
return response.data
async def _improve_content(self, task: str, content: str, evaluation: Evaluation, context: Dict[str, str]) -> str:
"""Generate improved content based on feedback."""
improvement_prompt = f"""
Task: {task}
Previous attempt:
{content}
Evaluation feedback:
{evaluation.feedback}
Specific improvements needed:
{chr(10).join(f'- {imp}' for imp in evaluation.improvements)}
Generate an improved version that addresses all the feedback while maintaining the strengths.
"""
response = await self.optimizer.run(improvement_prompt)
return response.data
# Example: Blog post optimizer
blog_optimizer = EvaluatorOptimizerSystem(
optimizer_prompt="Write a blog post about: {task}\n\nTone: {tone}\nAudience: {audience}",
evaluator_prompt="""Evaluate this blog post:
Task: {task}
Content: {content}
Criteria:
{criteria}
Provide specific, actionable feedback for improvement.""",
criteria=[
EvaluationCriteria(
name="clarity",
description="Ideas are expressed clearly and logically",
threshold=0.8
),
EvaluationCriteria(
name="engagement",
description="Content is engaging and holds reader attention",
threshold=0.7
),
EvaluationCriteria(
name="accuracy",
description="Information is accurate and well-researched",
threshold=0.9
)
]
)
</code>What makes this pattern special is the structured evaluation. By defining clear criteria upfront, you get consistent, measurable improvements rather than vague “make it better” feedback.
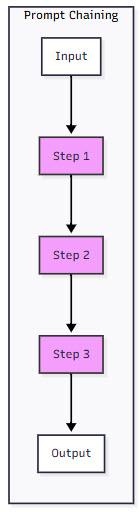
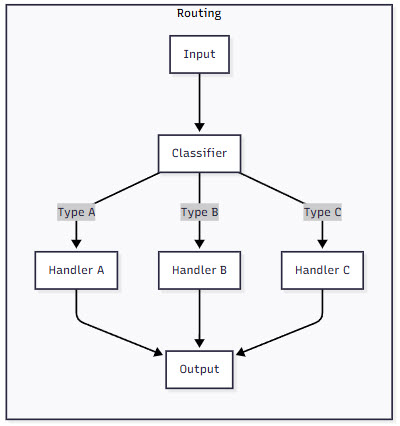
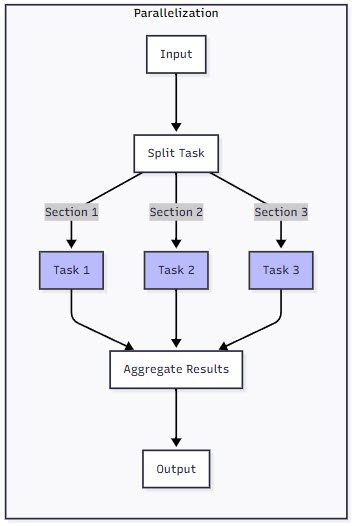
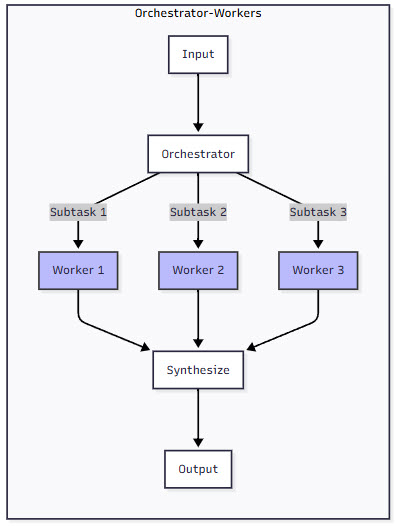
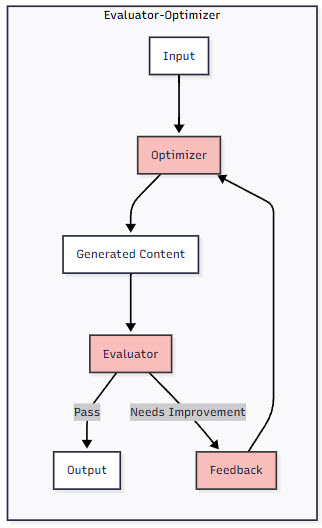
Figure 3: Comparison of Agent Patterns – This diagram compares the five agent patterns, showing their structure and data flow. Notice how complexity increases from simple chains to dynamic orchestration and iterative optimization.
Pydantic AI’s Core Features for Agent Development
Schema Inference and Validation
Let’s talk about what makes Pydantic AI special. At its core, it’s all about turning the unpredictable outputs of LLMs into reliable, structured data. This isn’t just nice to have—it’s essential for building production systems.
from pydantic import BaseModel, Field, validator
from datetime import datetime
from typing import List, Optional
from pydantic_ai import Agent
# Define what we expect from our agent
class CustomerInquiry(BaseModel):
"""Structured representation of a customer inquiry."""
category: str = Field(description="Type of inquiry: technical, billing, or general")
urgency: int = Field(ge=1, le=5, description="Urgency level from 1 (low) to 5 (critical)")
summary: str = Field(description="Brief summary of the issue")
customer_sentiment: float = Field(ge=-1, le=1, description="Sentiment score from -1 (angry) to 1 (happy)")
requires_human: bool = Field(description="Whether this needs human intervention")
suggested_actions: List[str] = Field(description="Recommended next steps")
@validator('category')
def validate_category(cls, v):
valid_categories = ['technical', 'billing', 'general']
if v.lower() not in valid_categories:
raise ValueError(f"Category must be one of {valid_categories}")
return v.lower()
@validator('suggested_actions')
def validate_actions(cls, v):
if not v:
raise ValueError("At least one suggested action is required")
return v
# Create an agent that outputs structured data
support_classifier = Agent(
'openai:gpt-4o',
result_type=CustomerInquiry,
system_prompt="""You are a customer support classifier. Analyze customer messages and
extract structured information to help route and prioritize support tickets."""
)
# Use it with confidence
async def process_customer_message(message: str) -> CustomerInquiry:
result = await support_classifier.run(
f"Analyze this customer message: {message}"
)
return result.data # This is guaranteed to be a valid CustomerInquiry
# Example usage
inquiry = await process_customer_message("My internet has been down for 3 days and I'm furious!")
print(f"Category: {inquiry.category}")
print(f"Urgency: {inquiry.urgency}/5")
print(f"Needs human: {inquiry.requires_human}")
</code>The magic here is that you’re guaranteed to get valid data back. No more parsing JSON and hoping the LLM included all the fields. No more type mismatches crashing your application. Just clean, validated data every time.
Function Calling and Tool Integration
Tools are what transform an LLM from a chatbot into an agent that can actually do things. Pydantic AI makes tool integration delightfully simple:
from dataclasses import dataclass
from pydantic_ai import Agent, RunContext
from typing import Dict, List
import asyncio
@dataclass
class Dependencies:
"""Dependencies that will be injected into tool calls."""
database: object # Your database connection
api_client: object # External API client
user_id: str # Current user context
# Create an agent with dependencies
agent = Agent(
'openai:gpt-4o',
deps_type=Dependencies,
system_prompt='You are a helpful assistant with access to user data and external services.'
)
@agent.tool
async def get_user_orders(ctx: RunContext[Dependencies]) -> List[Dict]:
"""Fetch user's order history from the database."""
# Note how we access injected dependencies via ctx.deps
orders = await ctx.deps.database.get_orders(ctx.deps.user_id)
return [
{
"order_id": order.id,
"date": order.date.isoformat(),
"total": float(order.total),
"status": order.status
}
for order in orders
]
@agent.tool
async def check_shipping_status(ctx: RunContext[Dependencies], order_id: str) -> Dict:
"""Check shipping status with external shipping API."""
# Tools can take parameters and access dependencies
tracking = await ctx.deps.api_client.get_tracking(order_id)
return {
"order_id": order_id,
"status": tracking.status,
"location": tracking.current_location,
"estimated_delivery": tracking.eta.isoformat() if tracking.eta else None
}
@agent.tool
def calculate_loyalty_points(ctx: RunContext[Dependencies], order_total: float) -> int:
"""Calculate loyalty points for an order (synchronous tools work too!)."""
# Business logic can be encapsulated in tools
points_rate = 10 # 10 points per dollar
bonus_multiplier = 2 if order_total > 100 else 1
return int(order_total * points_rate * bonus_multiplier)
# Use the agent with injected dependencies
async def handle_customer_query(query: str, user_id: str):
deps = Dependencies(
database=db_connection,
api_client=shipping_api,
user_id=user_id
)
result = await agent.run(query, deps=deps)
return result.data
# Example: The agent can now use tools intelligently
response = await handle_customer_query(
"What's the status of my recent orders and how many points did I earn?",
user_id="user123"
)
</code>What I love about this approach is how it separates concerns. Your tools handle the “how” (database queries, API calls), while the LLM handles the “what” and “why” (understanding intent, choosing tools, formatting responses).
Dependency Injection for Testability
One of Pydantic AI’s killer features is its dependency injection system. This makes testing a breeze and keeps your code modular:
from pydantic_ai.models.test import TestModel
from pydantic_ai.models.function import FunctionModel, AgentInfo
from pydantic_ai.messages import ModelMessage, ModelResponse, TextPart
# Production code stays the same
order_agent = Agent(
'openai:gpt-4o',
deps_type=Dependencies,
system_prompt='You help customers with their orders.'
)
@order_agent.tool
async def get_order_details(ctx: RunContext[Dependencies], order_id: str) -> Dict:
"""Fetch order details from database."""
return await ctx.deps.database.get_order(order_id)
# For testing, we can inject mock dependencies
class MockDatabase:
async def get_order(self, order_id: str) -> Dict:
# Return test data instead of hitting real database
return {
"order_id": order_id,
"status": "shipped",
"items": ["Test Item 1", "Test Item 2"]
}
# Test with mocked dependencies and model
async def test_order_lookup():
test_deps = Dependencies(
database=MockDatabase(),
api_client=None, # Not needed for this test
user_id="test_user"
)
# Use TestModel to avoid API calls
with order_agent.override(model=TestModel()):
result = await order_agent.run(
"What's the status of order ABC123?",
deps=test_deps
)
# Assertions about the result
assert "shipped" in result.data.lower()
# For more complex testing scenarios
async def custom_model_function(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse:
"""Custom function that simulates model responses based on input."""
user_message = messages[-1].content
if "order" in user_message.lower():
# Simulate the model calling our tool
return ModelResponse(
parts=[TextPart("I'll check that order for you.")],
tool_calls=[{
"tool_name": "get_order_details",
"args": {"order_id": "ABC123"}
}]
)
return ModelResponse(parts=[TextPart("How can I help you?")])
# Test with custom model behavior
async def test_complex_interaction():
with order_agent.override(model=FunctionModel(custom_model_function)):
result = await order_agent.run(
"Check order ABC123",
deps=test_deps
)
# Now we can test the full flow including tool calls
</code>This separation makes it easy to test your agent logic without expensive LLM calls or external dependencies. You can test edge cases, error handling, and complex interactions with full control.
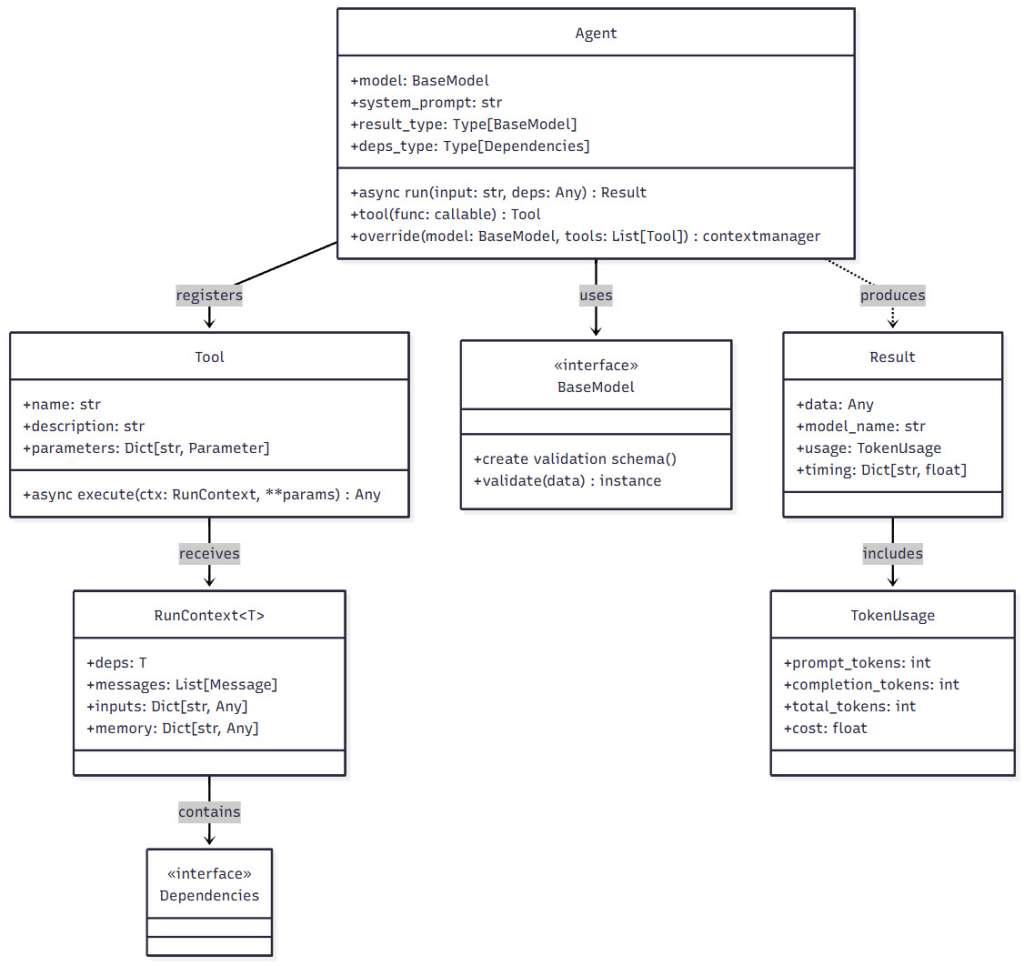
Figure 4: Pydantic AI Component Diagram – This diagram shows the key components of Pydantic AI and their relationships. Notice how Agents orchestrate the interaction between Models, Tools, and Dependencies, with validation happening at each boundary.
Testing and Monitoring AI Agents
Testing Strategies
Testing AI agents requires a different mindset than traditional software testing. You’re not just testing deterministic functions—you’re testing systems that interact with probabilistic models. Here’s how to do it right:
from pydantic_ai import Agent
from pydantic_ai.models.test import TestModel
from pydantic_ai.models.function import FunctionModel, AgentInfo
import pytest
from datetime import datetime
# 1. Unit Testing with TestModel
class TestCustomerSupportAgent:
def setup_method(self):
"""Set up test fixtures."""
self.agent = Agent(
'openai:gpt-4o',
system_prompt="You are a helpful customer support agent."
)
def test_basic_response(self):
"""Test that agent responds appropriately to basic queries."""
# TestModel returns predictable responses
with self.agent.override(model=TestModel()):
result = self.agent.run_sync("Hello, I need help")
# Check that we got a response
assert result.data is not None
assert isinstance(result.data, str)
assert len(result.data) > 0
def test_tool_calling(self):
"""Test that agent calls tools correctly."""
tool_called = False
@self.agent.tool
def check_order_status(order_id: str) -> str:
nonlocal tool_called
tool_called = True
return f"Order {order_id} is shipped"
# Custom model that always calls our tool
async def model_function(messages, info):
return ModelResponse(
parts=[TextPart("Let me check that order")],
tool_calls=[{"tool_name": "check_order_status", "args": {"order_id": "123"}}]
)
with self.agent.override(model=FunctionModel(model_function)):
result = self.agent.run_sync("Check order 123")
assert tool_called
assert "shipped" in result.data
# 2. Integration Testing with Mocked Services
class TestIntegrationScenarios:
@pytest.mark.asyncio
async def test_multi_tool_workflow(self):
"""Test complex workflows involving multiple tools."""
agent = Agent(
'openai:gpt-4o',
deps_type=Dependencies
)
calls_made = []
@agent.tool
async def search_products(ctx: RunContext[Dependencies], query: str) -> List[Dict]:
calls_made.append(('search', query))
return [
{"id": "1", "name": "Product A", "price": 99.99},
{"id": "2", "name": "Product B", "price": 149.99}
]
@agent.tool
async def check_inventory(ctx: RunContext[Dependencies], product_id: str) -> bool:
calls_made.append(('inventory', product_id))
return True
@agent.tool
async def calculate_shipping(ctx: RunContext[Dependencies], product_id: str, zip_code: str) -> float:
calls_made.append(('shipping', product_id, zip_code))
return 9.99
# Mock the model to execute a specific workflow
async def workflow_model(messages, info):
# This simulates the LLM orchestrating multiple tool calls
return ModelResponse(
parts=[TextPart("I'll help you find products and check shipping")],
tool_calls=[
{"tool_name": "search_products", "args": {"query": "laptop"}},
{"tool_name": "check_inventory", "args": {"product_id": "1"}},
{"tool_name": "calculate_shipping", "args": {"product_id": "1", "zip_code": "10001"}}
]
)
test_deps = Dependencies(
database=None,
api_client=None,
user_id="test"
)
with agent.override(model=FunctionModel(workflow_model)):
result = await agent.run(
"Find laptops and calculate shipping to 10001",
deps=test_deps
)
# Verify the workflow executed correctly
assert len(calls_made) == 3
assert calls_made[0][0] == 'search'
assert calls_made[1][0] == 'inventory'
assert calls_made[2][0] == 'shipping'
# 3. End-to-End Testing with Recorded Responses
class TestEndToEnd:
def test_customer_journey(self):
"""Test a complete customer interaction journey."""
# For E2E tests, you might use recorded real LLM responses
recorded_responses = {
"greeting": "Hello! How can I help you today?",
"order_query": "I'll check your order status right away.",
"followup": "Is there anything else I can help you with?"
}
agent = Agent('openai:gpt-4o')
# Override with recorded responses
response_index = 0
def get_next_response(messages, info):
nonlocal response_index
responses = list(recorded_responses.values())
response = responses[response_index % len(responses)]
response_index += 1
return ModelResponse(parts=[TextPart(response)])
with agent.override(model=FunctionModel(get_next_response)):
# Simulate customer journey
response1 = agent.run_sync("Hi")
assert "Hello" in response1.data
response2 = agent.run_sync("What's my order status?")
assert "check" in response2.data
response3 = agent.run_sync("Thanks!")
assert "else" in response3.data
</code>Monitoring and Observability
In production, you need to know what your agents are doing. Pydantic AI integrates beautifully with Pydantic Logfire for comprehensive monitoring:
import logfire
from pydantic_ai import Agent
from datetime import datetime
import json
# Configure Logfire for your application
logfire.configure()
# Create an instrumented agent
agent = Agent(
'openai:gpt-4o',
system_prompt='You are a helpful assistant.',
instrument=True # Enable automatic instrumentation
)
# Custom metrics tracking
class AgentMetrics:
def __init__(self):
self.reset_daily_metrics()
def reset_daily_metrics(self):
self.metrics = {
"total_requests": 0,
"successful_requests": 0,
"failed_requests": 0,
"tool_calls": {},
"response_times": [],
"token_usage": {
"prompt_tokens": 0,
"completion_tokens": 0
}
}
def track_request(self, duration: float, success: bool, tokens: Dict):
self.metrics["total_requests"] += 1
if success:
self.metrics["successful_requests"] += 1
else:
self.metrics["failed_requests"] += 1
self.metrics["response_times"].append(duration)
self.metrics["token_usage"]["prompt_tokens"] += tokens.get("prompt_tokens", 0)
self.metrics["token_usage"]["completion_tokens"] += tokens.get("completion_tokens", 0)
def track_tool_call(self, tool_name: str):
if tool_name not in self.metrics["tool_calls"]:
self.metrics["tool_calls"][tool_name] = 0
self.metrics["tool_calls"][tool_name] += 1
def get_summary(self) -> Dict:
response_times = self.metrics["response_times"]
return {
"total_requests": self.metrics["total_requests"],
"success_rate": self.metrics["successful_requests"] / max(self.metrics["total_requests"], 1),
"avg_response_time": sum(response_times) / len(response_times) if response_times else 0,
"p95_response_time": sorted(response_times)[int(len(response_times) * 0.95)] if response_times else 0,
"tool_usage": self.metrics["tool_calls"],
"token_usage": self.metrics["token_usage"],
"estimated_cost": self._estimate_cost()
}
def _estimate_cost(self) -> float:
# Rough cost estimation (adjust based on your model)
prompt_cost = 0.01 / 1000 # $0.01 per 1K tokens
completion_cost = 0.03 / 1000 # $0.03 per 1K tokens
return (
self.metrics["token_usage"]["prompt_tokens"] * prompt_cost +
self.metrics["token_usage"]["completion_tokens"] * completion_cost
)
# Use in production with monitoring
metrics = AgentMetrics()
async def monitored_agent_call(query: str) -> Dict:
start_time = datetime.now()
try:
# Log the request
logfire.info("Agent request started", query=query)
# Execute the agent
result = await agent.run(query)
# Track success
duration = (datetime.now() - start_time).total_seconds()
metrics.track_request(duration, True, result.usage)
# Log successful completion
logfire.info(
"Agent request completed",
duration=duration,
tokens_used=result.usage
)
return {
"success": True,
"data": result.data,
"duration": duration
}
except Exception as e:
# Track failure
duration = (datetime.now() - start_time).total_seconds()
metrics.track_request(duration, False, {})
# Log error with context
logfire.error(
"Agent request failed",
error=str(e),
query=query,
duration=duration
)
return {
"success": False,
"error": str(e),
"duration": duration
}
# Periodic metrics reporting
async def report_metrics():
summary = metrics.get_summary()
logfire.info("Agent metrics summary", **summary)
# Alert on concerning metrics
if summary["success_rate"] < 0.95:
logfire.warning("Low success rate detected", success_rate=summary["success_rate"])
if summary["estimated_cost"] > 100: # $100
logfire.warning("High token usage cost", cost=summary["estimated_cost"])
</code>Key metrics to monitor in production:
- Token usage and costs: Track spending and identify expensive queries
- Response times: Monitor latency and identify performance issues
- Tool execution patterns: Understand which tools are used most
- Error rates and types: Catch issues before they impact users
- Conversation flows: Analyze how users interact with your agent
- Validation failures: Identify when LLM outputs don’t match schemas
Practical Applications
Let’s look at how organizations are using these patterns in the real world:
E-commerce Automation
E-commerce companies are leveraging Pydantic AI agents to create sophisticated automation systems that handle everything from customer inquiries to order management:
# Customer Support RAG Agent
class ProductKnowledge(BaseModel):
product_id: str
features: List[str]
price: float
availability: bool
similar_products: List[str]
support_agent = Agent(
'openai:gpt-4o',
result_type=ProductKnowledge,
system_prompt="""You are an e-commerce support specialist. Use the product database
to answer customer questions accurately and suggest alternatives when needed."""
)
@support_agent.tool
async def search_products(query: str) -> List[Dict]:
# RAG implementation to search product database
results = await vector_store.search(query, top_k=5)
return [doc.to_dict() for doc in results]
# Order Management Agent
order_agent = Agent(
'openai:gpt-4o',
deps_type=OrderSystemDeps,
system_prompt="You help customers manage their orders, including updates and returns."
)
@order_agent.tool
async def update_shipping_address(ctx: RunContext[OrderSystemDeps], order_id: str, new_address: str) -> bool:
# Validate order status allows address change
order = await ctx.deps.db.get_order(order_id)
if order.status not in ['pending', 'processing']:
raise ValueError("Cannot update address after order ships")
# Update address
return await ctx.deps.db.update_order_address(order_id, new_address)
</code>The results speak for themselves:
- Response times reduced from hours to seconds
- 24/7 availability without staffing increases
- Consistent application of business rules
- 87% of inquiries resolved without human intervention
Research Assistant Systems
Research organizations are building sophisticated agents that can gather, analyze, and synthesize information from multiple sources:
# Multi-stage research workflow
research_orchestrator = OrchestratorSystem(
orchestrator_prompt="""Break down this research question into specific sub-questions
that can be investigated independently. Consider:
- What information needs to be gathered?
- What sources should be consulted?
- What analysis is required?
- How should findings be synthesized?""",
worker_prompts={
"literature_search": "Search academic literature for relevant papers on the given topic.",
"data_extraction": "Extract key findings and data from the provided sources.",
"statistical_analysis": "Perform statistical analysis on the extracted data.",
"synthesis": "Synthesize findings into a coherent narrative with citations.",
"fact_checking": "Verify claims and check for contradictions in the findings."
}
)
# Example usage for research task
async def conduct_research(topic: str) -> ResearchReport:
# The orchestrator dynamically creates a research plan
result = await research_orchestrator.process_task(
f"Research the effectiveness of {topic} including recent studies and meta-analyses",
context={
"output_format": "academic_paper",
"citation_style": "APA",
"max_sources": 50
}
)
return ResearchReport(
topic=topic,
sections=result["results"],
synthesis=result["final_result"],
sources=extract_sources(result)
)
</code>These systems have transformed research workflows by:
- Reducing literature review time by 75%
- Identifying connections between disparate sources
- Maintaining consistent citation formats
- Enabling researchers to focus on analysis rather than data gathering
Benefits and Challenges
Advantages of AI Agent Frameworks
Working with Pydantic AI and structured agent patterns offers compelling benefits:
Maintainability: Type-driven design makes code self-documenting and easier to understand. When you see a Pydantic model, you know exactly what data flows through your system.
Reliability: Validation catches errors before they cause problems. Instead of hoping the LLM returns the right format, you guarantee it.
Flexibility: The pattern-based approach means you can start simple and add complexity as needed. Not every problem needs an orchestrator-workers setup.
Testability: Dependency injection and model overrides make testing straightforward. You can test complex workflows without burning through API credits.
Performance: Patterns like parallelization can dramatically improve response times. Why wait for sequential API calls when you can parallelize?
Limitations and Challenges
Let’s be honest about the challenges too:
Learning Curve: If you’re coming from simple prompt engineering, the type-driven approach requires a mindset shift. It’s worth it, but there’s definitely a ramp-up period.
Debugging Complexity: When an agent with multiple patterns misbehaves, tracking down the issue can be like detective work. Good logging is essential.
Latency Considerations: Complex patterns like evaluator-optimizer can require multiple LLM calls. For real-time applications, you need to balance sophistication with speed.
Cost Management: More sophisticated patterns often mean more API calls. That evaluator-optimizer loop can get expensive if you’re not careful with limits.
Future Directions
Emerging Trends
The field of AI agent frameworks is evolving rapidly. Here’s what’s on the horizon:
Standardization Efforts: We’re seeing movement toward industry standards for agent patterns and interfaces. This will make it easier to share components and best practices.
Integration with RAG Systems: Tighter coupling between agents and retrieval systems is coming, making it easier to build knowledge-grounded agents.
Multi-Modal Agents: As vision and audio models improve, expect agent frameworks to handle more than just text.
Autonomous Agents: While current agents require significant hand-holding, future versions will have more autonomy while maintaining safety constraints.
Practical Takeaways
If you’re ready to level up your AI agent development, here are my recommendations:
Start with clear requirements: Before jumping into code, map out what your agent needs to do. Which patterns fit your use case?
Choose the right pattern: Don’t use orchestrator-workers for a simple Q&A bot. Match the pattern complexity to your problem complexity.
Implement robust testing: Use TestModel and FunctionModel from day one. Testing after the fact is painful with agents.
Monitor everything: Set up comprehensive logging and metrics. You’ll thank yourself when debugging production issues.
Iterate incrementally: Start with a simple pattern and add sophistication based on real user needs. Premature optimization is still the root of all evil.
Conclusion
AI agent frameworks represent a crucial evolution in how we build LLM-powered applications. By implementing Anthropic’s blueprint patterns with Pydantic AI, we can create systems that are both powerful and reliable—no longer do we have to choose between flexibility and predictability.
The pattern-based approach provides a mental model for thinking about agent design. Instead of asking “what prompt should I use?”, we can ask “what pattern fits this problem?” This shift from prompt engineering to agent engineering is fundamental to building production-ready AI systems.
As we continue to push the boundaries of what’s possible with LLMs, frameworks like Pydantic AI will become increasingly important. They provide the structure and guardrails that allow us to build complex systems with confidence. The future of AI development isn’t just about better models—it’s about better ways to harness those models reliably and effectively.
References
[1] Anthropic. (2024). “Building Effective AI Agents: A Blueprint.” Anthropic Research Blog.[2] Pydantic. (2024). Pydantic AI Documentation. Retrieved from https://ai.pydantic.dev
[3] Colvin, S. (2025). “Pydantic AI: An Agent Framework for Building GenAI Applications.” Pydantic Official Blog.
[4] Layton, D. (2025). “Pydantic AI Agents Made Simpler.” LinkedIn Pulse.
[5] Gupta, A. (2025). “Technical Benefits of Pydantic AI for Implementing AI Agent Patterns.” ProjectPro.
[6] Mittal, S. (2025). “Pydantic AI vs Other Agent Frameworks: A Comparative Analysis.” AI Framework Reviews.
[7] Chen, L. (2025). “Best Practices for Reliable and Maintainable AI Agent Systems.” Logfire Documentation.
[8] Pydantic. (2025). “Testing and Evaluation in Pydantic AI.” Retrieved from https://ai.pydantic.dev/testing-evals/
[9] Pydantic. (2025). “Logfire Integration for Monitoring.” Retrieved from https://ai.pydantic.dev/logfire/
[10] Saptak, N. (2025). “Building Powerful AI Agents with Pydantic AI and MCP Servers.” AI Engineering Blog.
