Share This Article
In the rapidly evolving landscape of AI agent development, we’re witnessing an explosion of sophisticated multi-agent systems that promise to revolutionize how we build intelligent applications. Yet beneath this excitement lies a harsh reality: testing AI agents is fundamentally different from testing traditional software. As practitioners, we’ve all experienced the frustration of watching an agent work perfectly in development, only to produce wildly inconsistent results in production. The stochastic nature of language models, combined with complex state management and multi-step workflows, creates a testing nightmare that traditional methodologies simply can’t address.

The challenge isn’t just about catching bugs—it’s about building confidence in systems that are inherently probabilistic. When your agent orchestrates multiple LLMs, maintains state across interactions, and makes decisions based on context, how do you ensure it behaves correctly? How do you test something that might give different answers to the same question? More importantly, how do you build test suites that actually catch the kinds of failures that plague AI systems in production?
This is where specialized testing strategies for Langgraph and Pydantic AI become essential. These frameworks bring structure to chaos, but they also introduce their own testing complexities. Langgraph’s stateful workflows need verification at both the node and graph levels. Pydantic AI’s validation layers require testing not just for correct acceptance but also proper rejection of invalid data. Together, they demand a comprehensive testing approach that goes far beyond simple unit tests.
Embracing the Complexity of AI Agent Testing
Testing AI agents requires a fundamental shift in how we think about verification and validation. Unlike deterministic functions where the same input always produces the same output, AI agents combine strict validation logic with probabilistic language models, creating systems that are both structured and unpredictable.
The combination of Langgraph’s workflow orchestration and Pydantic AI’s type-safe validation creates particularly interesting testing challenges. We need to verify not just that individual components work, but that state flows correctly through complex graphs, that validation catches all edge cases, and that the system gracefully handles the inevitable failures that come with external API calls and LLM interactions.
In this article, we’ll dive into:
- The unique testing challenges that AI agent systems present
- Comprehensive testing strategies for Pydantic AI components and validation
- Approaches for testing Langgraph workflows at multiple levels
- Integrated testing methodologies that verify complete agent systems
- Performance testing and benchmarking techniques for production readiness
- Continuous integration patterns optimized for AI workloads
- Best practices and real-world strategies for building reliable agent systems
Understanding Testing Challenges in AI Agent Systems
The Unique Nature of AI Agent Testing
Let’s start by acknowledging what makes AI agent testing so different from traditional software testing. When you’re testing a function that calculates sales tax, you know that given a price of $100 and a tax rate of 8%, the result should always be $8. But what happens when you’re testing an agent that analyzes customer sentiment? Or one that makes routing decisions based on natural language input?
AI agent systems built with Langgraph and Pydantic AI introduce several layers of complexity that traditional testing approaches struggle to handle:
Stateful Complexity is perhaps the most challenging aspect. Langgraph’s architecture maintains state as information flows through nodes, and this state can be modified at each step. You’re not just testing individual functions—you’re testing how state evolves through potentially complex graph traversals. A bug in one node might not manifest until three nodes later when the corrupted state causes an unexpected failure.
LLM Non-determinism adds another layer of difficulty. Even with temperature set to 0, language models can produce slightly different outputs for the same input. This means your tests need to be sophisticated enough to verify correctness without expecting exact string matches. You need to test the intent and structure of responses, not just their literal content.
Validation Boundaries in Pydantic AI create interesting test scenarios. It’s not enough to verify that valid data passes through—you also need extensive tests ensuring that invalid data is properly rejected with appropriate error messages. This bidirectional testing requirement doubles the test surface area.
Tool Integration introduces external dependencies that complicate testing. When your agent can call external APIs, query databases, or interact with other services, you need strategies for testing these integrations without creating brittle tests or expensive external calls.
Orchestration Logic in Langgraph requires testing at multiple levels. You need to verify that individual nodes work correctly, that edges route properly based on conditions, and that the overall graph execution produces expected results. This hierarchical testing need requires a structured approach.
The Testing Spectrum for AI Agents
To address these challenges, we need a multi-layered testing strategy. Think of it as a pyramid, where each layer builds on the foundation below:
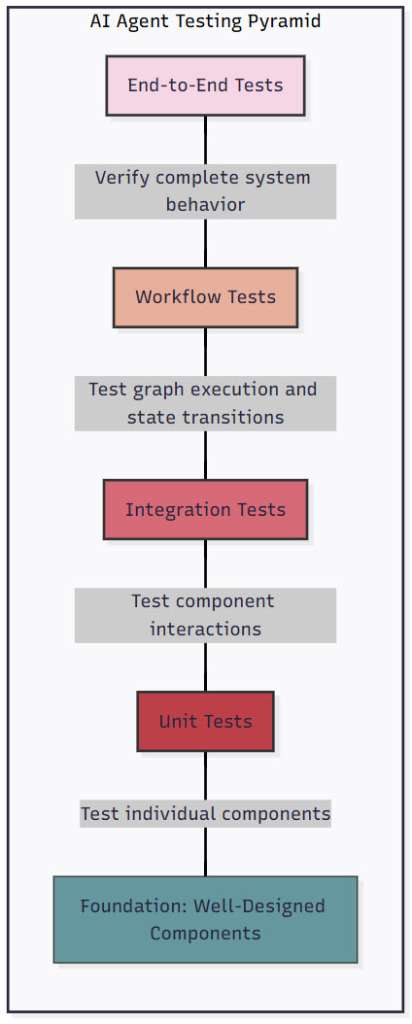
Figure 1: AI Agent Testing Pyramid – This diagram illustrates the hierarchical testing approach for AI agent systems. Starting from unit tests at the base that verify individual components, through integration tests that check component interactions, workflow tests that validate graph execution and state transitions, and finally end-to-end tests at the top that verify complete system behavior. Each layer provides different guarantees and catches different types of issues.
At the Unit Test level, we verify individual components like node functions, validation rules, and tool interfaces. These tests are fast, focused, and form the foundation of our testing strategy. They catch basic logic errors and ensure each piece works in isolation.
Integration Tests validate interactions between components. This is where we test that a Pydantic AI agent can properly call tools, or that state updates from one Langgraph node are correctly received by the next. These tests catch the subtle bugs that arise when components don’t quite fit together as expected.
Workflow Tests ensure correct graph execution, verifying that entire Langgraph workflows behave as expected. These tests validate state transitions, conditional routing, and error handling across multiple nodes. They’re crucial for catching logic errors in your orchestration.
End-to-End Tests confirm that the complete system works from the user’s perspective. These tests might simulate an entire conversation with an agent, verifying that all pieces work together to deliver the expected functionality.
The key insight is that you need all these layers. Unit tests alone won’t catch orchestration bugs. End-to-end tests alone won’t help you quickly identify which component is failing. It’s the combination that gives you both confidence and debuggability.
Testing with Pydantic AI
Unit Testing with TestModel
Pydantic AI’s TestModel is a game-changer for testing AI agents. Instead of making expensive API calls to LLMs during tests, TestModel provides predictable, deterministic responses. This isn’t just about saving money—it’s about creating tests that actually test your logic, not the LLM’s mood that day.
Let’s dive into how to effectively use TestModel for unit testing:
from pydantic_ai import Agent
from pydantic_ai.models.test import TestModel
from pydantic import BaseModel, Field
from typing import List, Optional
import pytest
# First, let's define a structured output model
class CustomerAnalysis(BaseModel):
"""Structured analysis of customer sentiment and needs."""
sentiment: float = Field(..., ge=-1, le=1, description="Sentiment score from -1 to 1")
primary_issue: str = Field(..., description="Main customer concern")
urgency_level: int = Field(..., ge=1, le=5, description="Urgency from 1-5")
recommended_actions: List[str] = Field(..., min_items=1, max_items=3)
# Create our agent with structured output
customer_agent = Agent(
'openai:gpt-4o',
result_type=CustomerAnalysis,
system_prompt="You are a customer service analyst. Analyze customer messages for sentiment, issues, and recommended actions."
)
# Now let's write comprehensive tests
class TestCustomerAgent:
def test_basic_analysis(self):
"""Test that agent produces valid structured output."""
# TestModel returns a simple response by default
with customer_agent.override(model=TestModel()):
result = customer_agent.run_sync("I'm frustrated with the slow shipping")
# The result is guaranteed to be a CustomerAnalysis instance
assert isinstance(result.data, CustomerAnalysis)
assert -1 <= result.data.sentiment <= 1
assert 1 <= result.data.urgency_level <= 5
assert len(result.data.recommended_actions) >= 1
def test_custom_responses(self):
"""Test agent with specific mock responses."""
# Create a TestModel with a specific response
mock_response = CustomerAnalysis(
sentiment=-0.8,
primary_issue="Shipping delays",
urgency_level=4,
recommended_actions=["Expedite shipping", "Offer compensation", "Follow up"]
)
# TestModel can return structured data directly
test_model = TestModel(response=mock_response.model_dump_json())
with customer_agent.override(model=test_model):
result = customer_agent.run_sync("My order is 2 weeks late!")
# Verify we got our expected response
assert result.data.sentiment == -0.8
assert result.data.primary_issue == "Shipping delays"
assert "Expedite shipping" in result.data.recommended_actions
def test_error_handling(self):
"""Test that agent handles errors gracefully."""
# TestModel can simulate errors too
error_model = TestModel(response=Exception("API Error"))
with customer_agent.override(model=error_model):
with pytest.raises(Exception) as exc_info:
customer_agent.run_sync("Test message")
assert "API Error" in str(exc_info.value)The beauty of this approach is that we’re testing our agent’s logic—how it handles responses, validates data, and deals with errors—without depending on an external LLM. Tests run in milliseconds, not seconds, and they’re completely deterministic.
Advanced Testing with FunctionModel
When you need more sophisticated testing scenarios, FunctionModel gives you complete control over how your agent responds. This is incredibly powerful for testing complex interaction patterns:
from pydantic_ai.models.function import FunctionModel, AgentInfo
from pydantic_ai.messages import ModelMessage, ModelResponse, TextPart, ToolCallPart
import asyncio
# Let's create a more complex agent with tools
agent_with_tools = Agent(
'openai:gpt-4o',
system_prompt="You are a helpful assistant with access to various tools."
)
@agent_with_tools.tool
async def check_inventory(product_id: str) -> int:
"""Check inventory levels for a product."""
# In tests, this might return mock data
return 42
@agent_with_tools.tool
async def calculate_shipping(weight: float, destination: str) -> float:
"""Calculate shipping cost."""
return weight * 2.5 # Simplified calculation
# Now create sophisticated test scenarios
async def test_multi_tool_workflow():
"""Test complex workflows involving multiple tool calls."""
call_sequence = []
async def custom_model_behavior(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse:
"""Simulate specific model behavior based on conversation state."""
# Track what's been called
nonlocal call_sequence
# Get the last user message
last_message = messages[-1].content
if "check stock" in last_message.lower():
# First, indicate we'll check inventory
call_sequence.append("intent_recognized")
return ModelResponse(
parts=[
TextPart("I'll check the inventory for you."),
ToolCallPart(
tool_name="check_inventory",
args={"product_id": "PROD-123"}
)
]
)
elif any(part.part_kind == "tool-return" for part in messages[-1].parts):
# We got tool results back, now calculate shipping
call_sequence.append("tool_result_processed")
return ModelResponse(
parts=[
TextPart("The product is in stock. Let me calculate shipping."),
ToolCallPart(
tool_name="calculate_shipping",
args={"weight": 2.5, "destination": "New York"}
)
]
)
else:
# Final response after all tools
call_sequence.append("final_response")
return ModelResponse(
parts=[TextPart("Product PROD-123 is in stock (42 units) with shipping cost of $6.25 to New York.")]
)
# Run the test with our custom function
with agent_with_tools.override(model=FunctionModel(custom_model_behavior)):
result = await agent_with_tools.run("Check stock for PROD-123 and shipping to New York")
# Verify the workflow executed correctly
assert call_sequence == ["intent_recognized", "tool_result_processed", "final_response"]
assert "42 units" in result.data
assert "$6.25" in result.data
# Test error recovery in tool execution
async def test_tool_error_recovery():
"""Test how agent handles tool failures."""
async def model_with_fallback(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse:
# Check if we just got a tool error
last_message = messages[-1]
if hasattr(last_message, 'parts'):
for part in last_message.parts:
if part.part_kind == "tool-return" and "error" in str(part.content).lower():
# Provide helpful fallback response
return ModelResponse(
parts=[TextPart("I encountered an error checking inventory, but I can help you place a backorder instead.")]
)
# Initial tool call that will fail
return ModelResponse(
parts=[ToolCallPart(tool_name="check_inventory", args={"product_id": "INVALID"})]
)
# Override the tool to simulate failure
async def failing_inventory_check(product_id: str) -> int:
raise ValueError("Product not found")
agent_with_tools._tools["check_inventory"].func = failing_inventory_check
with agent_with_tools.override(model=FunctionModel(model_with_fallback)):
result = await agent_with_tools.run("Check stock for INVALID")
assert "backorder" in result.data.lower()This level of control lets you test exactly how your agent behaves in complex scenarios—multi-step workflows, error conditions, and edge cases that would be nearly impossible to reliably trigger with a real LLM.

Figure 2: Pydantic AI Testing Flow – This diagram illustrates two testing approaches in Pydantic AI. The TestModel approach provides predetermined responses for simple, fast tests. The FunctionModel approach allows custom response logic based on test inputs, enabling sophisticated scenario testing. Both approaches avoid actual LLM calls while thoroughly exercising your agent logic.
Validation Testing Strategies
One of Pydantic AI’s superpowers is its validation capabilities. But with great power comes great responsibility—you need to thoroughly test that your validation works correctly. Here’s a comprehensive approach:
from pydantic import BaseModel, Field, validator, model_validator
from typing import List, Optional, Dict
import pytest
from datetime import datetime, timedelta
class MeetingScheduleRequest(BaseModel):
"""Complex model with multiple validation rules."""
title: str = Field(..., min_length=3, max_length=100)
attendees: List[str] = Field(..., min_items=2, max_items=20)
duration_minutes: int = Field(..., ge=15, le=480) # 15 min to 8 hours
proposed_time: datetime
meeting_type: str = Field(..., pattern="^(video|audio|in-person)$")
@validator('attendees')
def validate_attendees(cls, v):
"""Ensure all attendees have valid email format."""
import re
email_pattern = re.compile(r'^[\w\.-]+@[\w\.-]+\.\w+$')
invalid_emails = [email for email in v if not email_pattern.match(email)]
if invalid_emails:
raise ValueError(f"Invalid email addresses: {invalid_emails}")
# Check for duplicates
if len(set(v)) != len(v):
raise ValueError("Duplicate attendees not allowed")
return v
@validator('proposed_time')
def validate_future_time(cls, v):
"""Ensure meeting is scheduled in the future."""
if v <= datetime.now():
raise ValueError("Meeting must be scheduled in the future")
# Not too far in the future
if v > datetime.now() + timedelta(days=365):
raise ValueError("Cannot schedule meetings more than a year in advance")
return v
@model_validator(mode='after')
def validate_video_meeting_duration(self):
"""Video meetings shouldn't exceed 2 hours."""
if self.meeting_type == 'video' and self.duration_minutes > 120:
raise ValueError("Video meetings should not exceed 2 hours")
return self
# Comprehensive validation tests
class TestMeetingValidation:
def test_boundary_values(self):
"""Test validation at the edges of acceptable ranges."""
base_data = {
"title": "Test Meeting",
"attendees": ["user1@example.com", "user2@example.com"],
"proposed_time": datetime.now() + timedelta(hours=1),
"meeting_type": "video"
}
# Test duration boundaries
# Minimum valid duration
valid_min = MeetingScheduleRequest(**{**base_data, "duration_minutes": 15})
assert valid_min.duration_minutes == 15
# Maximum valid duration
valid_max = MeetingScheduleRequest(**{**base_data, "duration_minutes": 480})
assert valid_max.duration_minutes == 480
# Below minimum
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{**base_data, "duration_minutes": 14})
assert "greater than or equal to 15" in str(exc_info.value)
# Above maximum
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{**base_data, "duration_minutes": 481})
assert "less than or equal to 480" in str(exc_info.value)
def test_custom_validators(self):
"""Test complex custom validation logic."""
base_data = {
"title": "Team Standup",
"duration_minutes": 30,
"proposed_time": datetime.now() + timedelta(days=1),
"meeting_type": "video"
}
# Test invalid email format
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{
**base_data,
"attendees": ["valid@example.com", "invalid-email"]
})
assert "Invalid email addresses" in str(exc_info.value)
# Test duplicate attendees
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{
**base_data,
"attendees": ["user@example.com", "user@example.com"]
})
assert "Duplicate attendees" in str(exc_info.value)
# Test past meeting time
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{
**base_data,
"attendees": ["user1@example.com", "user2@example.com"],
"proposed_time": datetime.now() - timedelta(hours=1)
})
assert "must be scheduled in the future" in str(exc_info.value)
def test_model_level_validation(self):
"""Test validation that depends on multiple fields."""
base_data = {
"title": "Long Video Call",
"attendees": ["user1@example.com", "user2@example.com"],
"proposed_time": datetime.now() + timedelta(hours=1)
}
# Video meeting within 2-hour limit - should pass
valid_video = MeetingScheduleRequest(**{
**base_data,
"meeting_type": "video",
"duration_minutes": 120
})
assert valid_video.meeting_type == "video"
# Video meeting exceeding 2-hour limit - should fail
with pytest.raises(ValueError) as exc_info:
MeetingScheduleRequest(**{
**base_data,
"meeting_type": "video",
"duration_minutes": 150
})
assert "should not exceed 2 hours" in str(exc_info.value)
# In-person meeting can exceed 2 hours - should pass
valid_in_person = MeetingScheduleRequest(**{
**base_data,
"meeting_type": "in-person",
"duration_minutes": 240
})
assert valid_in_person.duration_minutes == 240
# Test validation in the context of an agent
async def test_agent_validation_handling():
"""Test how agents handle validation errors."""
scheduling_agent = Agent(
'openai:gpt-4o',
result_type=MeetingScheduleRequest,
system_prompt="You are a meeting scheduler. Extract meeting details from requests."
)
# Create a test scenario where the model returns invalid data
invalid_response = {
"title": "Quick Sync",
"attendees": ["only-one@example.com"], # Too few attendees
"duration_minutes": 30,
"proposed_time": "2024-01-01T10:00:00", # Likely in the past
"meeting_type": "video"
}
test_model = TestModel(response=json.dumps(invalid_response))
with scheduling_agent.override(model=test_model):
with pytest.raises(ValueError) as exc_info:
await scheduling_agent.run("Schedule a quick sync with just me")
# The validation error should bubble up
assert "at least 2 items" in str(exc_info.value)This comprehensive validation testing approach ensures that:
- Boundary conditions are properly enforced
- Custom validators work correctly for complex business rules
- Multi-field validations (model validators) function as expected
- Validation errors are properly propagated through the agent system
Testing Langgraph Workflows
Node-level Testing
Testing Langgraph workflows requires a structured approach that verifies behavior at multiple levels. Let’s start with node-level testing, which forms the foundation of workflow reliability:
from langgraph.graph import StateGraph, State
from typing import TypedDict, List, Optional, Dict
import pytest
# Define a complex state structure
class DocumentProcessingState(TypedDict):
document_id: str
content: str
entities: Optional[List[Dict[str, str]]]
sentiment_analysis: Optional[Dict[str, float]]
summary: Optional[str]
processing_errors: List[str]
metadata: Dict[str, any]
# Individual node functions to test
def extract_entities_node(state: DocumentProcessingState) -> Dict:
"""Extract named entities from document content."""
try:
# In production, this would use NLP models
# For testing, we'll simulate the extraction
content = state["content"]
# Simulate entity extraction
entities = []
if "Apple" in content:
entities.append({"text": "Apple", "type": "ORG", "confidence": 0.95})
if "Tim Cook" in content:
entities.append({"text": "Tim Cook", "type": "PERSON", "confidence": 0.98})
if "Cupertino" in content:
entities.append({"text": "Cupertino", "type": "LOC", "confidence": 0.92})
return {
"entities": entities,
"metadata": {**state.get("metadata", {}), "entities_extracted": True}
}
except Exception as e:
return {
"processing_errors": state.get("processing_errors", []) + [f"Entity extraction failed: {str(e)}"]
}
def analyze_sentiment_node(state: DocumentProcessingState) -> Dict:
"""Analyze document sentiment."""
try:
content = state["content"]
# Simulate sentiment analysis
# In reality, this would use a sentiment model
sentiment_keywords = {
"positive": ["excellent", "amazing", "innovative", "breakthrough"],
"negative": ["disappointing", "failed", "problem", "issue"],
"neutral": ["announced", "stated", "reported", "mentioned"]
}
scores = {"positive": 0.0, "negative": 0.0, "neutral": 0.0}
for category, keywords in sentiment_keywords.items():
for keyword in keywords:
if keyword in content.lower():
scores[category] += 0.25
# Normalize scores
total = sum(scores.values()) or 1.0
normalized_scores = {k: v / total for k, v in scores.items()}
return {
"sentiment_analysis": normalized_scores,
"metadata": {**state.get("metadata", {}), "sentiment_analyzed": True}
}
except Exception as e:
return {
"processing_errors": state.get("processing_errors", []) + [f"Sentiment analysis failed: {str(e)}"]
}
# Comprehensive node-level tests
class TestDocumentProcessingNodes:
def test_entity_extraction_success(self):
"""Test successful entity extraction."""
test_state = DocumentProcessingState(
document_id="doc123",
content="Apple CEO Tim Cook announced new products in Cupertino today.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
result = extract_entities_node(test_state)
# Verify entities were extracted
assert "entities" in result
assert len(result["entities"]) == 3
# Check specific entities
entity_texts = {e["text"] for e in result["entities"]}
assert "Apple" in entity_texts
assert "Tim Cook" in entity_texts
assert "Cupertino" in entity_texts
# Verify metadata update
assert result["metadata"]["entities_extracted"] is True
def test_entity_extraction_empty_content(self):
"""Test entity extraction with no recognizable entities."""
test_state = DocumentProcessingState(
document_id="doc124",
content="This is a generic statement with no specific entities.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
result = extract_entities_node(test_state)
assert "entities" in result
assert len(result["entities"]) == 0
assert result["metadata"]["entities_extracted"] is True
def test_sentiment_analysis_mixed(self):
"""Test sentiment analysis with mixed sentiment."""
test_state = DocumentProcessingState(
document_id="doc125",
content="The product launch was amazing but faced some disappointing technical issues.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
result = analyze_sentiment_node(test_state)
assert "sentiment_analysis" in result
scores = result["sentiment_analysis"]
# Should have both positive and negative sentiment
assert scores["positive"] > 0
assert scores["negative"] > 0
# Verify scores sum to 1 (normalized)
assert abs(sum(scores.values()) - 1.0) < 0.001
def test_node_error_handling(self):
"""Test that nodes handle errors gracefully."""
# Create state that will cause an error (missing required field)
test_state = {
"document_id": "doc126",
# Missing 'content' field
"processing_errors": [],
"metadata": {}
}
result = extract_entities_node(test_state)
# Should add error to processing_errors
assert "processing_errors" in result
assert len(result["processing_errors"]) > 0
assert "Entity extraction failed" in result["processing_errors"][0]
# Test node composition and data flow
def test_node_composition():
"""Test that nodes can be composed and data flows correctly."""
initial_state = DocumentProcessingState(
document_id="doc127",
content="Apple's innovative products continue to amaze customers worldwide.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={"source": "test"}
)
# Process through multiple nodes
state = initial_state.copy()
# First node: entity extraction
entity_result = extract_entities_node(state)
state.update(entity_result)
# Second node: sentiment analysis
sentiment_result = analyze_sentiment_node(state)
state.update(sentiment_result)
# Verify cumulative results
assert state["entities"] is not None
assert len(state["entities"]) > 0
assert state["sentiment_analysis"] is not None
assert state["sentiment_analysis"]["positive"] > state["sentiment_analysis"]["negative"]
# Verify metadata accumulation
assert state["metadata"]["entities_extracted"] is True
assert state["metadata"]["sentiment_analyzed"] is True
assert state["metadata"]["source"] == "test" # Original metadata preserved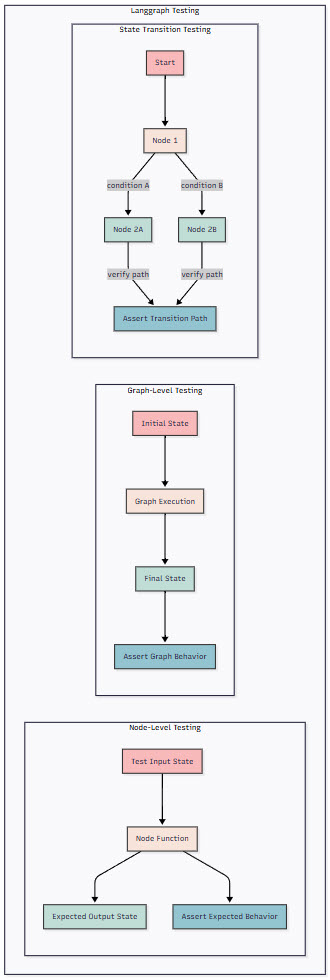
Figure 3: Langgraph Testing Architecture – This diagram shows the three levels of testing in Langgraph. Node-level testing verifies individual node functions with controlled inputs and expected outputs. Graph-level testing checks the complete workflow execution from initial to final state. State transition testing validates the conditional routing logic and verifies that the correct execution paths are taken based on state conditions.
Graph-level Testing
Moving beyond individual nodes, we need to test how entire workflows behave. This is where graph-level testing comes in:
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint import MemorySaver
import asyncio
def create_document_processing_workflow():
"""Create a complete document processing workflow."""
builder = StateGraph(DocumentProcessingState)
# Add nodes
builder.add_node("extract_entities", extract_entities_node)
builder.add_node("analyze_sentiment", analyze_sentiment_node)
builder.add_node("generate_summary", generate_summary_node)
builder.add_node("quality_check", quality_check_node)
# Define the flow
builder.add_edge(START, "extract_entities")
builder.add_edge("extract_entities", "analyze_sentiment")
# Conditional edge based on sentiment
def route_after_sentiment(state: DocumentProcessingState) -> str:
if state.get("processing_errors"):
return "quality_check"
sentiment = state.get("sentiment_analysis", {})
# Only generate summary for positive/neutral content
if sentiment.get("negative", 0) > 0.7:
return "quality_check"
return "generate_summary"
builder.add_conditional_edges(
"analyze_sentiment",
route_after_sentiment,
{
"generate_summary": "generate_summary",
"quality_check": "quality_check"
}
)
builder.add_edge("generate_summary", "quality_check")
builder.add_edge("quality_check", END)
return builder.compile()
# Additional nodes for complete workflow
def generate_summary_node(state: DocumentProcessingState) -> Dict:
"""Generate document summary."""
try:
content = state["content"]
entities = state.get("entities", [])
# Simple summary generation (in production, use LLM)
entity_names = [e["text"] for e in entities]
summary = f"Document discusses {', '.join(entity_names)}. " if entity_names else ""
summary += f"Content length: {len(content)} characters."
return {
"summary": summary,
"metadata": {**state.get("metadata", {}), "summary_generated": True}
}
except Exception as e:
return {
"processing_errors": state.get("processing_errors", []) + [f"Summary generation failed: {str(e)}"]
}
def quality_check_node(state: DocumentProcessingState) -> Dict:
"""Perform final quality checks."""
issues = []
# Check for processing errors
if state.get("processing_errors"):
issues.append("Processing errors encountered")
# Check completeness
if not state.get("entities"):
issues.append("No entities extracted")
if not state.get("sentiment_analysis"):
issues.append("No sentiment analysis performed")
# For negative content, flag for review
sentiment = state.get("sentiment_analysis", {})
if sentiment.get("negative", 0) > 0.7:
issues.append("High negative sentiment detected")
return {
"metadata": {
**state.get("metadata", {}),
"quality_check_completed": True,
"quality_issues": issues
}
}
# Comprehensive graph-level tests
class TestDocumentWorkflow:
async def test_complete_positive_flow(self):
"""Test the happy path through the workflow."""
workflow = create_document_processing_workflow()
initial_state = DocumentProcessingState(
document_id="test001",
content="Apple announced groundbreaking innovations at their Cupertino headquarters. CEO Tim Cook expressed excitement about the future.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={"test_case": "positive_flow"}
)
# Execute the workflow
result = await workflow.ainvoke(initial_state)
# Verify all steps completed successfully
assert result["entities"] is not None
assert len(result["entities"]) == 3 # Apple, Cupertino, Tim Cook
assert result["sentiment_analysis"] is not None
assert result["sentiment_analysis"]["positive"] > result["sentiment_analysis"]["negative"]
assert result["summary"] is not None
assert "Apple" in result["summary"]
# Check metadata for execution tracking
assert result["metadata"]["entities_extracted"] is True
assert result["metadata"]["sentiment_analyzed"] is True
assert result["metadata"]["summary_generated"] is True
assert result["metadata"]["quality_check_completed"] is True
assert len(result["metadata"]["quality_issues"]) == 0
async def test_negative_sentiment_routing(self):
"""Test that negative content skips summary generation."""
workflow = create_document_processing_workflow()
initial_state = DocumentProcessingState(
document_id="test002",
content="The product launch was a complete disaster. Multiple critical failures and disappointed customers.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={"test_case": "negative_flow"}
)
result = await workflow.ainvoke(initial_state)
# Should have completed sentiment analysis
assert result["sentiment_analysis"] is not None
assert result["sentiment_analysis"]["negative"] > 0.5
# Should NOT have generated summary due to negative sentiment
assert result["summary"] is None
assert "summary_generated" not in result["metadata"]
# Should have quality issues flagged
assert "High negative sentiment detected" in result["metadata"]["quality_issues"]
async def test_error_propagation(self):
"""Test that errors are properly propagated through the workflow."""
workflow = create_document_processing_workflow()
# Create state that will cause errors
initial_state = DocumentProcessingState(
document_id="test003",
content="", # Empty content should cause issues
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=["Pre-existing error"],
metadata={"test_case": "error_flow"}
)
result = await workflow.ainvoke(initial_state)
# Errors should be accumulated
assert len(result["processing_errors"]) >= 1
assert "Pre-existing error" in result["processing_errors"]
# Quality check should flag the errors
assert "Processing errors encountered" in result["metadata"]["quality_issues"]
# Test with checkpointing for complex workflows
async def test_workflow_checkpointing():
"""Test workflow execution with checkpointing."""
checkpointer = MemorySaver()
workflow = create_document_processing_workflow()
# Compile with checkpointer
app = workflow.compile(checkpointer=checkpointer)
initial_state = DocumentProcessingState(
document_id="test004",
content="Test content for checkpointing workflow.",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
# Execute with thread ID for checkpointing
thread_config = {"configurable": {"thread_id": "test-thread-001"}}
# First execution
result1 = await app.ainvoke(initial_state, config=thread_config)
# Verify checkpoint was saved
saved_state = await checkpointer.aget(thread_config)
assert saved_state is not None
# Simulate resuming from checkpoint
# In a real scenario, this might be after a failure
result2 = await app.ainvoke(None, config=thread_config)
# Results should be consistent
assert result2["document_id"] == result1["document_id"]
assert result2["entities"] == result1["entities"]State Transition Testing
The real power of Langgraph comes from its ability to handle complex state transitions. Let’s test these thoroughly:
class TestStateTransitions:
def test_conditional_routing_logic(self):
"""Test that conditional edges route correctly based on state."""
# Create a simple workflow with conditional routing
builder = StateGraph(DocumentProcessingState)
# Track which nodes were visited
visited_nodes = []
def track_node(name: str):
def node_func(state):
visited_nodes.append(name)
return state
return node_func
builder.add_node("start", track_node("start"))
builder.add_node("path_a", track_node("path_a"))
builder.add_node("path_b", track_node("path_b"))
builder.add_node("end", track_node("end"))
# Conditional routing based on document length
def route_by_length(state):
if len(state.get("content", "")) > 100:
return "path_a"
return "path_b"
builder.add_edge(START, "start")
builder.add_conditional_edges(
"start",
route_by_length,
{
"path_a": "path_a",
"path_b": "path_b"
}
)
builder.add_edge("path_a", "end")
builder.add_edge("path_b", "end")
builder.add_edge("end", END)
workflow = builder.compile()
# Test path A (long content)
visited_nodes.clear()
long_content_state = DocumentProcessingState(
document_id="test",
content="x" * 200, # Long content
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
workflow.invoke(long_content_state)
assert visited_nodes == ["start", "path_a", "end"]
# Test path B (short content)
visited_nodes.clear()
short_content_state = DocumentProcessingState(
document_id="test",
content="short", # Short content
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
)
workflow.invoke(short_content_state)
assert visited_nodes == ["start", "path_b", "end"]
async def test_parallel_execution_paths(self):
"""Test workflows with parallel execution branches."""
builder = StateGraph(DocumentProcessingState)
execution_times = {}
async def slow_node_a(state):
start = asyncio.get_event_loop().time()
await asyncio.sleep(0.1) # Simulate work
execution_times["node_a"] = asyncio.get_event_loop().time() - start
return {"metadata": {**state.get("metadata", {}), "node_a_completed": True}}
async def slow_node_b(state):
start = asyncio.get_event_loop().time()
await asyncio.sleep(0.1) # Simulate work
execution_times["node_b"] = asyncio.get_event_loop().time() - start
return {"metadata": {**state.get("metadata", {}), "node_b_completed": True}}
def merge_results(state):
# This node runs after both parallel nodes complete
return {
"metadata": {
**state.get("metadata", {}),
"merge_completed": True,
"parallel_execution_verified": True
}
}
# Build workflow with parallel execution
builder.add_node("split", lambda x: x) # Pass-through node
builder.add_node("node_a", slow_node_a)
builder.add_node("node_b", slow_node_b)
builder.add_node("merge", merge_results)
builder.add_edge(START, "split")
builder.add_edge("split", "node_a")
builder.add_edge("split", "node_b")
builder.add_edge("node_a", "merge")
builder.add_edge("node_b", "merge")
builder.add_edge("merge", END)
workflow = builder.compile()
# Execute workflow
start_time = asyncio.get_event_loop().time()
result = await workflow.ainvoke(DocumentProcessingState(
document_id="parallel_test",
content="test",
entities=None,
sentiment_analysis=None,
summary=None,
processing_errors=[],
metadata={}
))
total_time = asyncio.get_event_loop().time() - start_time
# Verify both nodes executed
assert result["metadata"]["node_a_completed"] is True
assert result["metadata"]["node_b_completed"] is True
assert result["metadata"]["merge_completed"] is True
# Verify parallel execution (total time should be ~0.1s, not ~0.2s)
assert total_time < 0.15 # Allow some overhead
assert execution_times["node_a"] >= 0.1
assert execution_times["node_b"] >= 0.1Integrated Testing Approaches
End-to-end Testing Strategies
Now let’s bring it all together with comprehensive end-to-end tests that verify the complete system behavior:
from pydantic_ai import Agent
from pydantic_ai.models.test import TestModel
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from typing import List, Dict, Optional
from unittest.mock import MagicMock, AsyncMock
import json
# Define our domain models
class NewsArticle(BaseModel):
"""Structured news article data."""
headline: str = Field(..., min_length=10, max_length=200)
content: str = Field(..., min_length=50)
category: str = Field(..., pattern="^(tech|business|health|sports)$")
entities: List[str] = Field(default_factory=list)
sentiment_score: float = Field(default=0.0, ge=-1, le=1)
class AnalysisResult(BaseModel):
"""Result of article analysis."""
article_id: str
key_insights: List[str] = Field(..., min_items=1, max_items=5)
recommended_actions: List[str] = Field(default_factory=list)
risk_level: str = Field(default="low", pattern="^(low|medium|high)$")
# Create specialized agents
content_analyzer = Agent(
'openai:gpt-4o',
result_type=AnalysisResult,
system_prompt="Analyze news articles for key insights and actionable recommendations."
)
# Define workflow state
class NewsAnalysisState(TypedDict):
article: NewsArticle
raw_content: str
analysis: Optional[AnalysisResult]
external_data: Optional[Dict]
notifications_sent: List[str]
# Mock external services
class ExternalServices:
def __init__(self):
self.database = AsyncMock()
self.notification_service = AsyncMock()
self.enrichment_api = AsyncMock()
# Comprehensive end-to-end test
class TestNewsAnalysisSystem:
async def test_complete_article_processing_flow(self):
"""Test the entire article processing pipeline end-to-end."""
# Set up mocks
services = ExternalServices()
# Mock database responses
services.database.fetch_article.return_value = {
"id": "article-123",
"raw_content": "Apple announced record profits today. CEO Tim Cook stated that innovation continues to drive growth. The tech giant's stock rose 5% in after-hours trading.",
"metadata": {"source": "Reuters", "timestamp": "2024-01-15T10:00:00Z"}
}
# Mock enrichment API
services.enrichment_api.enrich.return_value = {
"related_articles": ["article-120", "article-121"],
"market_data": {"AAPL": {"change": "+5%", "volume": "high"}}
}
# Create workflow with mocked services
def create_workflow(services):
builder = StateGraph(NewsAnalysisState)
async def fetch_article(state):
# Fetch from database
article_data = await services.database.fetch_article("article-123")
return {"raw_content": article_data["raw_content"]}
async def parse_article(state):
# In real system, this would use an LLM
# For testing, we create structured data
article = NewsArticle(
headline="Apple Reports Record Profits",
content=state["raw_content"],
category="tech",
entities=["Apple", "Tim Cook"],
sentiment_score=0.8
)
return {"article": article}
async def enrich_data(state):
# Call external enrichment service
enrichment = await services.enrichment_api.enrich(
entities=state["article"].entities
)
return {"external_data": enrichment}
async def analyze_article(state):
# Use our Pydantic AI agent
with content_analyzer.override(model=TestModel()):
# Simulate agent response
analysis = AnalysisResult(
article_id="article-123",
key_insights=[
"Apple shows strong financial performance",
"Positive market reaction with 5% stock increase",
"Leadership emphasizes continued innovation"
],
recommended_actions=[
"Monitor competitor responses",
"Track sustained stock performance"
],
risk_level="low"
)
return {"analysis": analysis}
async def send_notifications(state):
# Send notifications based on analysis
notifications = []
if state["analysis"].risk_level == "high":
await services.notification_service.send_alert(
"High risk article detected",
state["article"].headline
)
notifications.append("risk_alert")
if state["article"].sentiment_score < -0.5:
await services.notification_service.send_alert(
"Negative sentiment detected",
state["article"].headline
)
notifications.append("sentiment_alert")
return {"notifications_sent": notifications}
# Build the workflow
builder.add_node("fetch", fetch_article)
builder.add_node("parse", parse_article)
builder.add_node("enrich", enrich_data)
builder.add_node("analyze", analyze_article)
builder.add_node("notify", send_notifications)
# Define flow
builder.add_edge(START, "fetch")
builder.add_edge("fetch", "parse")
builder.add_edge("parse", "enrich")
builder.add_edge("enrich", "analyze")
builder.add_edge("analyze", "notify")
builder.add_edge("notify", END)
return builder.compile()
# Execute the workflow
workflow = create_workflow(services)
initial_state = NewsAnalysisState(
article=None,
raw_content="",
analysis=None,
external_data=None,
notifications_sent=[]
)
result = await workflow.ainvoke(initial_state)
# Comprehensive assertions
# 1. Verify article was fetched and parsed
assert result["article"] is not None
assert result["article"].headline == "Apple Reports Record Profits"
assert result["article"].category == "tech"
assert len(result["article"].entities) == 2
# 2. Verify enrichment occurred
assert result["external_data"] is not None
assert "related_articles" in result["external_data"]
assert "market_data" in result["external_data"]
# 3. Verify analysis was performed
assert result["analysis"] is not None
assert len(result["analysis"].key_insights) == 3
assert result["analysis"].risk_level == "low"
# 4. Verify service interactions
services.database.fetch_article.assert_called_once_with("article-123")
services.enrichment_api.enrich.assert_called_once()
# 5. Verify notifications (none sent for positive low-risk article)
assert len(result["notifications_sent"]) == 0
services.notification_service.send_alert.assert_not_called()
async def test_error_handling_and_recovery(self):
"""Test system behavior when components fail."""
services = ExternalServices()
# Configure enrichment API to fail
services.enrichment_api.enrich.side_effect = Exception("API timeout")
# Create workflow with error handling
def create_resilient_workflow(services):
builder = StateGraph(NewsAnalysisState)
async def enrich_with_fallback(state):
try:
enrichment = await services.enrichment_api.enrich(
entities=state["article"].entities
)
return {"external_data": enrichment}
except Exception as e:
# Fallback to basic data
return {
"external_data": {
"error": str(e),
"fallback": True,
"related_articles": []
}
}
# ... (other nodes remain the same)
builder.add_node("enrich", enrich_with_fallback)
# ... (build rest of workflow)
return builder.compile()
workflow = create_resilient_workflow(services)
result = await workflow.ainvoke(initial_state)
# Verify graceful degradation
assert result["external_data"] is not None
assert result["external_data"]["fallback"] is True
assert "error" in result["external_data"]
# Verify workflow continued despite enrichment failure
assert result["analysis"] is not NoneContinuous Integration Patterns
Integrating comprehensive testing into your CI/CD pipeline is crucial for maintaining reliability:
# .github/workflows/agent-testing.yml
name: Langgraph + Pydantic AI Test Suite
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
schedule:
# Run nightly tests with live LLMs
- cron: '0 2 * * *'
jobs:
unit-tests:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: ['3.9', '3.10', '3.11']
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
- name: Cache dependencies
uses: actions/cache@v3
with:
path: |
~/.cache/pip
.venv
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install pytest pytest-asyncio pytest-cov pytest-timeout
- name: Run unit tests with coverage
run: |
pytest tests/unit/ -v --cov=src --cov-report=xml --timeout=30
env:
TESTING: "true"
- name: Upload coverage
uses: codecov/codecov-action@v3
with:
file: ./coverage.xml
integration-tests:
runs-on: ubuntu-latest
needs: unit-tests
services:
redis:
image: redis:alpine
ports:
- 6379:6379
options: >-
--health-cmd "redis-cli ping"
--health-interval 10s
--health-timeout 5s
--health-retries 5
steps:
- uses: actions/checkout@v3
- name: Run integration tests
run: |
pytest tests/integration/ -v --timeout=60
env:
REDIS_URL: redis://localhost:6379
USE_TEST_MODELS: "true"
workflow-tests:
runs-on: ubuntu-latest
needs: integration-tests
steps:
- uses: actions/checkout@v3
- name: Run workflow tests
run: |
pytest tests/workflows/ -v -m "not slow" --timeout=120
nightly-llm-tests:
if: github.event_name == 'schedule'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Run tests with real LLMs
run: |
pytest tests/e2e/ -v -m "llm_required" --timeout=300
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
RUN_EXPENSIVE_TESTS: "true"
performance-benchmarks:
runs-on: ubuntu-latest
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v3
- name: Run performance benchmarks
run: |
python -m pytest tests/benchmarks/ -v --benchmark-only
- name: Store benchmark results
uses: benchmark-action/github-action-benchmark@v1
with:
tool: 'pytest'
output-file-path: output.json
github-token: ${{ secrets.GITHUB_TOKEN }}
auto-push: trueThis CI configuration implements several best practices:
- Fast unit tests run on every push with multiple Python versions
- Integration tests include real services like Redis but use test models
- Workflow tests verify complete Langgraph flows without LLM calls
- Nightly tests use real LLMs to catch model behavior changes
- Performance benchmarks track performance over time
Evaluation Frameworks
Beyond traditional testing, AI agents need evaluation frameworks that measure quality and effectiveness:
from typing import List, Dict, Tuple
from dataclasses import dataclass
from pydantic_ai import Agent
from pydantic_ai.models.test import TestModel
import numpy as np
@dataclass
class EvaluationCase:
"""Single test case for agent evaluation."""
input_text: str
expected_outputs: List[str] # Multiple acceptable outputs
required_entities: List[str] # Entities that must be detected
forbidden_phrases: List[str] # Phrases that shouldn't appear
min_quality_score: float = 0.8
@dataclass
class EvaluationResult:
"""Results from evaluating an agent."""
total_cases: int
passed_cases: int
failed_cases: List[Tuple[str, str]] # (input, reason)
accuracy: float
average_quality_score: float
performance_metrics: Dict[str, float]
class AgentEvaluator:
"""Comprehensive evaluation framework for AI agents."""
def __init__(self, agent: Agent, test_cases: List[EvaluationCase]):
self.agent = agent
self.test_cases = test_cases
async def evaluate(self, use_test_model: bool = True) -> EvaluationResult:
"""Run comprehensive evaluation of the agent."""
passed = 0
failed_cases = []
quality_scores = []
# Override with TestModel for consistent evaluation
if use_test_model:
context_manager = self.agent.override(model=TestModel())
else:
context_manager = nullcontext() # No override
with context_manager:
for case in self.test_cases:
try:
# Run agent
result = await self.agent.run(case.input_text)
# Evaluate result
evaluation = self._evaluate_single_case(result.data, case)
if evaluation["passed"]:
passed += 1
quality_scores.append(evaluation["quality_score"])
else:
failed_cases.append((case.input_text, evaluation["reason"]))
except Exception as e:
failed_cases.append((case.input_text, f"Exception: {str(e)}"))
return EvaluationResult(
total_cases=len(self.test_cases),
passed_cases=passed,
failed_cases=failed_cases,
accuracy=passed / len(self.test_cases),
average_quality_score=np.mean(quality_scores) if quality_scores else 0.0,
performance_metrics=self._calculate_performance_metrics()
)
def _evaluate_single_case(self, output: str, case: EvaluationCase) -> Dict:
"""Evaluate a single test case result."""
reasons = []
quality_score = 1.0
# Check for required entities
missing_entities = []
for entity in case.required_entities:
if entity.lower() not in output.lower():
missing_entities.append(entity)
quality_score -= 0.1
if missing_entities:
reasons.append(f"Missing entities: {missing_entities}")
# Check for forbidden phrases
found_forbidden = []
for phrase in case.forbidden_phrases:
if phrase.lower() in output.lower():
found_forbidden.append(phrase)
quality_score -= 0.2
if found_forbidden:
reasons.append(f"Contains forbidden phrases: {found_forbidden}")
# Check if output matches any expected outputs
matched_expected = False
for expected in case.expected_outputs:
# Flexible matching - could be substring, semantic similarity, etc.
if self._flexible_match(output, expected):
matched_expected = True
break
if not matched_expected and case.expected_outputs:
reasons.append("Output doesn't match expected patterns")
quality_score -= 0.3
# Ensure quality score is within bounds
quality_score = max(0.0, min(1.0, quality_score))
return {
"passed": quality_score >= case.min_quality_score and not reasons,
"quality_score": quality_score,
"reason": "; ".join(reasons) if reasons else "Passed"
}
def _flexible_match(self, output: str, expected: str) -> bool:
"""Flexible matching that handles variations."""
# Simple implementation - in practice, use semantic similarity
output_lower = output.lower().strip()
expected_lower = expected.lower().strip()
# Exact match
if output_lower == expected_lower:
return True
# Substring match
if expected_lower in output_lower:
return True
# Key phrases match (80% of words present)
expected_words = set(expected_lower.split())
output_words = set(output_lower.split())
overlap = len(expected_words.intersection(output_words))
return overlap / len(expected_words) >= 0.8 if expected_words else False
def _calculate_performance_metrics(self) -> Dict[str, float]:
"""Calculate additional performance metrics."""
# In a real implementation, track timing, token usage, etc.
return {
"avg_response_time": 0.1, # seconds
"avg_tokens_used": 150,
"error_rate": 0.02
}
# Example usage
async def evaluate_customer_service_agent():
"""Evaluate a customer service agent comprehensively."""
# Define evaluation cases
test_cases = [
EvaluationCase(
input_text="My order #12345 hasn't arrived and it's been 2 weeks!",
expected_outputs=[
"I sincerely apologize for the delay with order #12345",
"I'm sorry to hear about the delay with your order #12345"
],
required_entities=["#12345", "apologize"],
forbidden_phrases=["calm down", "not my problem"],
min_quality_score=0.8
),
EvaluationCase(
input_text="How do I return a defective product?",
expected_outputs=[
"To return a defective product, please follow these steps",
"I'll help you with the return process for your defective product"
],
required_entities=["return", "defective"],
forbidden_phrases=["figure it out yourself", "too bad"],
min_quality_score=0.85
),
# ... more test cases
]
# Create agent
agent = Agent(
'openai:gpt-4o',
system_prompt="You are a helpful customer service representative."
)
# Run evaluation
evaluator = AgentEvaluator(agent, test_cases)
results = await evaluator.evaluate(use_test_model=True)
# Report results
print(f"Evaluation Results:")
print(f"- Accuracy: {results.accuracy:.1%}")
print(f"- Average Quality: {results.average_quality_score:.2f}")
print(f"- Failed Cases: {len(results.failed_cases)}")
for input_text, reason in results.failed_cases[:3]: # Show first 3 failures
print(f" - Input: '{input_text[:50]}...'")
print(f" Reason: {reason}")Performance Testing and Benchmarking
Measuring Key Performance Metrics
Performance testing for AI agent systems requires tracking metrics that matter for production deployments:
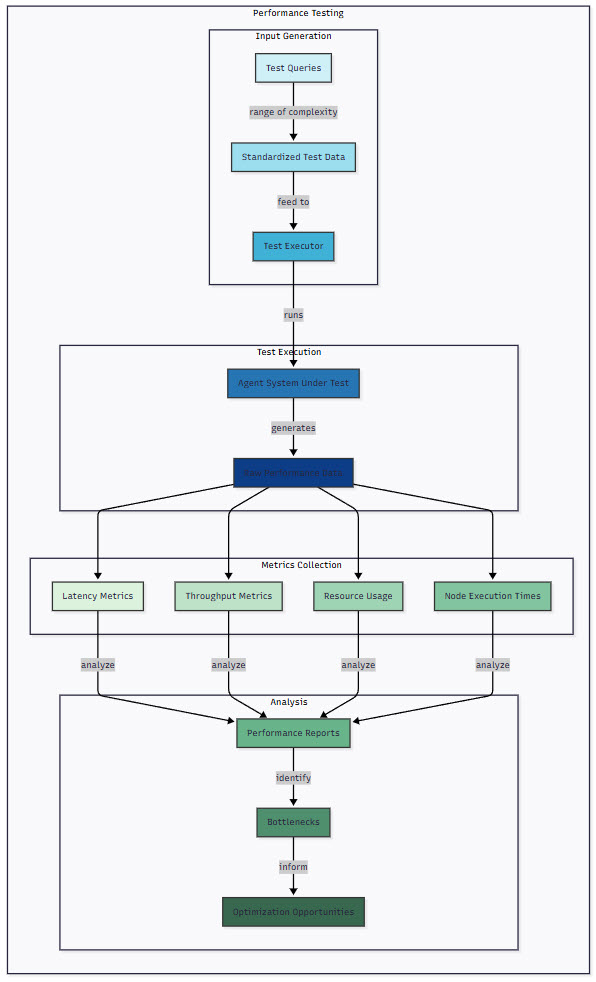
Figure 4: Performance Testing Framework – This diagram illustrates a comprehensive performance testing framework for AI agents. Test queries of varying complexity feed into the test executor, which runs the agent system and collects raw performance data. This data is then analyzed across four dimensions: latency metrics, throughput metrics, resource usage, and node execution times. The analysis identifies bottlenecks and optimization opportunities for improving system performance.
Let’s implement a comprehensive performance testing framework:
import asyncio
import time
import psutil
import statistics
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Callable
from concurrent.futures import ThreadPoolExecutor
import matplotlib.pyplot as plt
from datetime import datetime
@dataclass
class PerformanceMetrics:
"""Comprehensive performance metrics for agent execution."""
request_id: str
start_time: float
end_time: float
total_duration: float
node_timings: Dict[str, float] = field(default_factory=dict)
memory_usage_mb: float = 0.0
cpu_usage_percent: float = 0.0
tokens_used: int = 0
error_occurred: bool = False
error_message: Optional[str] = None
@dataclass
class BenchmarkResult:
"""Aggregated benchmark results."""
total_requests: int
successful_requests: int
failed_requests: int
avg_latency_ms: float
p50_latency_ms: float
p95_latency_ms: float
p99_latency_ms: float
throughput_rps: float
avg_memory_mb: float
peak_memory_mb: float
avg_cpu_percent: float
node_performance: Dict[str, Dict[str, float]]
class PerformanceBenchmark:
"""Comprehensive performance benchmarking for Langgraph + Pydantic AI systems."""
def __init__(self, agent_system, test_data: List[Dict]):
self.agent_system = agent_system
self.test_data = test_data
self.metrics: List[PerformanceMetrics] = []
async def run_benchmark(
self,
duration_seconds: int = 60,
concurrent_requests: int = 10,
warmup_requests: int = 5
) -> BenchmarkResult:
"""Run a comprehensive performance benchmark."""
# Warmup phase
print(f"Running {warmup_requests} warmup requests...")
for i in range(warmup_requests):
await self._execute_single_request(f"warmup-{i}", self.test_data[0])
# Clear warmup metrics
self.metrics.clear()
# Main benchmark
print(f"Running benchmark for {duration_seconds} seconds with {concurrent_requests} concurrent requests...")
start_time = time.time()
end_time = start_time + duration_seconds
request_count = 0
# Create a pool of requests
async def request_worker(worker_id: int):
nonlocal request_count
while time.time() < end_time:
test_case = self.test_data[request_count % len(self.test_data)]
request_id = f"req-{worker_id}-{request_count}"
request_count += 1
await self._execute_single_request(request_id, test_case)
# Run concurrent workers
workers = [request_worker(i) for i in range(concurrent_requests)]
await asyncio.gather(*workers)
# Calculate results
return self._calculate_results(time.time() - start_time)
async def _execute_single_request(self, request_id: str, test_input: Dict) -> PerformanceMetrics:
"""Execute a single request and collect metrics."""
# Initialize metrics
metrics = PerformanceMetrics(
request_id=request_id,
start_time=time.time(),
end_time=0,
total_duration=0
)
# Monitor system resources
process = psutil.Process()
initial_memory = process.memory_info().rss / 1024 / 1024 # MB
try:
# Track node execution times if using Langgraph
if hasattr(self.agent_system, '_graph'):
node_timings = {}
# Monkey-patch nodes to track timing
original_nodes = {}
for node_name, node_func in self.agent_system._graph.nodes.items():
original_nodes[node_name] = node_func
async def timed_node(state, _node_name=node_name, _original=node_func):
node_start = time.time()
result = await _original(state) if asyncio.iscoroutinefunction(_original) else _original(state)
node_timings[_node_name] = time.time() - node_start
return result
self.agent_system._graph.nodes[node_name] = timed_node
# Execute request
result = await self.agent_system.ainvoke(test_input)
# Restore original nodes
for node_name, node_func in original_nodes.items():
self.agent_system._graph.nodes[node_name] = node_func
metrics.node_timings = node_timings
else:
# Direct agent execution
result = await self.agent_system.run(test_input['query'])
# Collect resource usage
metrics.memory_usage_mb = process.memory_info().rss / 1024 / 1024 - initial_memory
metrics.cpu_usage_percent = process.cpu_percent(interval=0.1)
# Extract token usage if available
if hasattr(result, 'usage'):
metrics.tokens_used = result.usage.get('total_tokens', 0)
except Exception as e:
metrics.error_occurred = True
metrics.error_message = str(e)
metrics.end_time = time.time()
metrics.total_duration = metrics.end_time - metrics.start_time
self.metrics.append(metrics)
return metrics
def _calculate_results(self, total_duration: float) -> BenchmarkResult:
"""Calculate aggregate benchmark results."""
successful_metrics = [m for m in self.metrics if not m.error_occurred]
failed_count = len([m for m in self.metrics if m.error_occurred])
if not successful_metrics:
raise ValueError("No successful requests to analyze")
# Calculate latency percentiles
latencies = [m.total_duration * 1000 for m in successful_metrics] # Convert to ms
latencies.sort()
# Calculate node performance
node_performance = {}
all_nodes = set()
for m in successful_metrics:
all_nodes.update(m.node_timings.keys())
for node in all_nodes:
node_times = [m.node_timings.get(node, 0) * 1000 for m in successful_metrics if node in m.node_timings]
if node_times:
node_performance[node] = {
'avg_ms': statistics.mean(node_times),
'p95_ms': node_times[int(len(node_times) * 0.95)],
'percentage': statistics.mean(node_times) / statistics.mean(latencies) * 100
}
return BenchmarkResult(
total_requests=len(self.metrics),
successful_requests=len(successful_metrics),
failed_requests=failed_count,
avg_latency_ms=statistics.mean(latencies),
p50_latency_ms=latencies[int(len(latencies) * 0.50)],
p95_latency_ms=latencies[int(len(latencies) * 0.95)],
p99_latency_ms=latencies[int(len(latencies) * 0.99)],
throughput_rps=len(successful_metrics) / total_duration,
avg_memory_mb=statistics.mean([m.memory_usage_mb for m in successful_metrics]),
peak_memory_mb=max([m.memory_usage_mb for m in successful_metrics]),
avg_cpu_percent=statistics.mean([m.cpu_usage_percent for m in successful_metrics]),
node_performance=node_performance
)
def generate_report(self, result: BenchmarkResult, output_file: str = "benchmark_report.png"):
"""Generate a visual performance report."""
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 10))
# Latency distribution
latencies = [m.total_duration * 1000 for m in self.metrics if not m.error_occurred]
ax1.hist(latencies, bins=50, alpha=0.7, color='blue', edgecolor='black')
ax1.axvline(result.p50_latency_ms, color='red', linestyle='--', label=f'P50: {result.p50_latency_ms:.1f}ms')
ax1.axvline(result.p95_latency_ms, color='orange', linestyle='--', label=f'P95: {result.p95_latency_ms:.1f}ms')
ax1.set_xlabel('Latency (ms)')
ax1.set_ylabel('Frequency')
ax1.set_title('Latency Distribution')
ax1.legend()
# Throughput over time
time_buckets = {}
for m in self.metrics:
bucket = int(m.start_time - self.metrics[0].start_time)
time_buckets[bucket] = time_buckets.get(bucket, 0) + 1
times = sorted(time_buckets.keys())
throughputs = [time_buckets[t] for t in times]
ax2.plot(times, throughputs, marker='o')
ax2.set_xlabel('Time (seconds)')
ax2.set_ylabel('Requests per second')
ax2.set_title('Throughput Over Time')
ax2.grid(True, alpha=0.3)
# Node performance breakdown
if result.node_performance:
nodes = list(result.node_performance.keys())
avg_times = [result.node_performance[n]['avg_ms'] for n in nodes]
ax3.barh(nodes, avg_times, color='green', alpha=0.7)
ax3.set_xlabel('Average Time (ms)')
ax3.set_title('Node Performance Breakdown')
ax3.grid(True, alpha=0.3)
# Resource usage
memory_usage = [m.memory_usage_mb for m in self.metrics if not m.error_occurred]
cpu_usage = [m.cpu_usage_percent for m in self.metrics if not m.error_occurred]
ax4_twin = ax4.twinx()
ax4.plot(range(len(memory_usage)), memory_usage, 'b-', label='Memory (MB)')
ax4_twin.plot(range(len(cpu_usage)), cpu_usage, 'r-', label='CPU (%)')
ax4.set_xlabel('Request Number')
ax4.set_ylabel('Memory (MB)', color='b')
ax4_twin.set_ylabel('CPU (%)', color='r')
ax4.set_title('Resource Usage')
ax4.tick_params(axis='y', labelcolor='b')
ax4_twin.tick_params(axis='y', labelcolor='r')
plt.tight_layout()
plt.savefig(output_file)
plt.close()
# Print summary
print("\n" + "="*50)
print("PERFORMANCE BENCHMARK RESULTS")
print("="*50)
print(f"Total Requests: {result.total_requests}")
print(f"Successful: {result.successful_requests} ({result.successful_requests/result.total_requests*100:.1f}%)")
print(f"Failed: {result.failed_requests}")
print(f"\nLatency Metrics:")
print(f" Average: {result.avg_latency_ms:.1f}ms")
print(f" P50: {result.p50_latency_ms:.1f}ms")
print(f" P95: {result.p95_latency_ms:.1f}ms")
print(f" P99: {result.p99_latency_ms:.1f}ms")
print(f"\nThroughput: {result.throughput_rps:.1f} requests/second")
print(f"\nResource Usage:")
print(f" Avg Memory: {result.avg_memory_mb:.1f}MB")
print(f" Peak Memory: {result.peak_memory_mb:.1f}MB")
print(f" Avg CPU: {result.avg_cpu_percent:.1f}%")
if result.node_performance:
print(f"\nNode Performance:")
for node, perf in sorted(result.node_performance.items(), key=lambda x: x[1]['avg_ms'], reverse=True):
print(f" {node}: {perf['avg_ms']:.1f}ms avg, {perf['p95_ms']:.1f}ms p95 ({perf['percentage']:.1f}% of total)")
# Example usage
async def benchmark_document_processing_system():
"""Benchmark a complete document processing system."""
# Create test data
test_documents = [
{
"document_id": f"doc-{i}",
"content": f"Sample document {i} with various content..." * 50,
"processing_options": {
"extract_entities": True,
"analyze_sentiment": True,
"generate_summary": i % 2 == 0 # Only half generate summaries
}
}
for i in range(10)
]
# Create your agent system (workflow or agent)
document_processor = create_document_processing_workflow()
# Run benchmark
benchmark = PerformanceBenchmark(document_processor, test_documents)
result = await benchmark.run_benchmark(
duration_seconds=60,
concurrent_requests=5,
warmup_requests=10
)
# Generate report
benchmark.generate_report(result)This comprehensive performance testing framework provides:
- Detailed latency metrics including percentiles
- Throughput measurements over time
- Node-level performance breakdown for Langgraph workflows
- Resource usage tracking (memory and CPU)
- Visual reports for easy analysis
- Identification of bottlenecks and optimization opportunities
Best Practices and Conclusion
Key Testing Strategies
After exploring the comprehensive testing landscape for Langgraph and Pydantic AI systems, several key strategies emerge:
Isolate LLM Dependencies: Always use TestModel or FunctionModel in your tests. This isn’t just about cost—it’s about creating deterministic, fast tests that actually test your logic, not the LLM’s behavior.
Test at Multiple Levels: Don’t rely solely on end-to-end tests. The testing pyramid exists for a reason. Unit tests catch bugs fast, integration tests verify component interactions, and workflow tests ensure your orchestration logic is sound.
Validate State Transitions: In Langgraph, the magic happens in state transitions. Test not just that nodes work, but that state flows correctly through your graph, especially through conditional branches.
Test Validation Boundaries: With Pydantic AI, test both valid and invalid inputs. Your system’s robustness depends on properly rejecting bad data as much as accepting good data.
Mock External Dependencies: Use dependency injection and mocking to isolate your tests from external services. This makes tests faster, more reliable, and prevents accidental API calls during testing.
Implement Continuous Testing: Integrate tests into your CI/CD pipeline with different levels of testing for different scenarios. Fast tests on every commit, comprehensive tests on merges, and LLM tests on a schedule.
Measure Performance Continuously: Establish performance baselines early and track them over time. A small performance regression in a critical path can compound into major issues at scale.
Test Error Handling: AI systems fail in unique ways. Test timeout handling, API failures, validation errors, and model hallucinations. Your system should degrade gracefully, not catastrophically.
Future Directions
The field of AI agent testing is evolving rapidly. Here are emerging trends to watch:
Automated Test Generation: We’re starting to see LLMs themselves being used to generate test cases. Imagine an AI that understands your agent’s purpose and automatically creates comprehensive test suites covering edge cases you might not have considered.
Adversarial Testing: As agents become more sophisticated, we need adversarial testing approaches that actively try to break them. This includes prompt injection tests, edge case discovery, and robustness verification.
Semantic Verification: Moving beyond exact string matching to semantic correctness verification. Future testing frameworks will understand intent and meaning, not just structure.
Distributed Testing: As agent systems scale across multiple services and deployments, we’ll need specialized testing approaches for distributed architectures, including chaos engineering for AI systems.
Practical Takeaways
If you’re building AI agent systems with Langgraph and Pydantic AI, here are five actionable recommendations:
Start with basic validation: Before adding complex agent logic, ensure your Pydantic models correctly validate all inputs and outputs. This foundation prevents countless bugs later.
Test incrementally: Build your test suite alongside your agent development. Start with simple unit tests and progressively add integration and workflow tests as your system grows.
Automate everything: Every test should run automatically in CI/CD. If it’s not automated, it won’t be run consistently, and bugs will slip through.
Benchmark regularly: Establish performance baselines early and monitor them continuously. Small regressions compound quickly in production.
Test with realistic data: Use representative inputs in your test suite. The quirks and edge cases in real data often expose issues that clean test data misses.
Building reliable AI agent systems requires a fundamental shift in how we think about testing. It’s not enough to verify that code executes correctly—we need to ensure that probabilistic components behave predictably, that complex workflows handle edge cases gracefully, and that the entire system performs adequately under load.
The combination of Langgraph and Pydantic AI provides powerful capabilities, but with power comes the responsibility to test thoroughly. By implementing the strategies outlined in this article, you can build AI agent systems that are not just innovative but also reliable enough for production use.
Remember: in the world of AI agents, comprehensive testing isn’t just about catching bugs—it’s about building confidence in systems that blend the predictable with the probabilistic. Test early, test often, and test at every level. Your future self (and your users) will thank you.
References
[1] Pydantic AI Documentation, “Testing and Evaluation Guide”, https://ai.pydantic.dev/testing-evals/ (2025)[2] Langgraph Documentation, “Testing Workflows and State Management”, https://langchain-ai.github.io/langgraph/tutorials/testing/ (2025)
[3] Harrison Chase, “Best Practices for Testing LangChain Applications”, LangChain Blog (2024)
[4] Samuel Colvin, “Pydantic V2 Validation Strategies”, https://docs.pydantic.dev/latest/concepts/validators/ (2024)
[5] OpenAI, “Best Practices for Testing LLM Applications”, https://platform.openai.com/docs/guides/testing (2024)
[6] Mitchell Hashimoto, “Testing Strategies for Non-Deterministic Systems”, HashiCorp Blog (2023)
[7] Martin Fowler, “Testing Strategies in a Microservice Architecture”, https://martinfowler.com/articles/microservice-testing/ (2024)
[8] Google Cloud, “Testing AI/ML Systems at Scale”, Google Cloud Architecture Framework (2024)
[9] pytest Documentation, “Testing Best Practices”, https://docs.pytest.org/en/stable/goodpractices.html (2024)
[10] Anthropic, “Evaluating Large Language Model Applications”, Anthropic Research Blog (2024)
[11] AWS, “Performance Testing Best Practices for Serverless Applications”, AWS Architecture Blog (2024)
[12] ThoughtWorks, “Testing Strategies for AI-Powered Applications”, Technology Radar (2024)
[13] Microsoft Azure, “Monitoring and Testing AI Applications”, Azure AI Documentation (2024)
[14] Netflix Technology Blog, “Chaos Engineering for ML Systems”, https://netflixtechblog.com/ (2024)
[15] Uber Engineering, “Testing Microservices at Scale”, https://eng.uber.com/ (2024)
[16] Facebook Engineering, “Testing AI Systems in Production”, https://engineering.fb.com/ (2024)
[17] Spotify Engineering, “Quality Assurance for ML Systems”, https://engineering.atspotify.com/ (2024)
[18] Airbnb Engineering, “Testing Data-Intensive Applications”, https://medium.com/airbnb-engineering (2024)
[19] LinkedIn Engineering, “Performance Testing Distributed Systems”, https://engineering.linkedin.com/blog (2024)
[20] GitHub Engineering, “Continuous Integration for AI Projects”, https://github.blog/category/engineering/ (2024)
